Le MLOps unifie le développement des modèles d’apprentissage automatique et leur exploitation réelle pour garantir des prédictions fiables à long terme. Sans cette rigueur, vos algorithmes risquent de finir leur course dans un fossé, inutilisés.
Le MLOps, ou Machine Learning Operations, désigne un ensemble de pratiques d’ingénierie. Son but consiste à automatiser et simplifier le cycle de vie des modèles. Nous parlons ici de la conception initiale, du déploiement en production et de la maintenance. Ce domaine jette un pont solide entre la science des données, le DevOps et l’ingénierie des données. Notre objectif est de bâtir des systèmes d’intelligence artificielle robustes, stables et évolutifs.
Les étapes clés du cycle MLOps
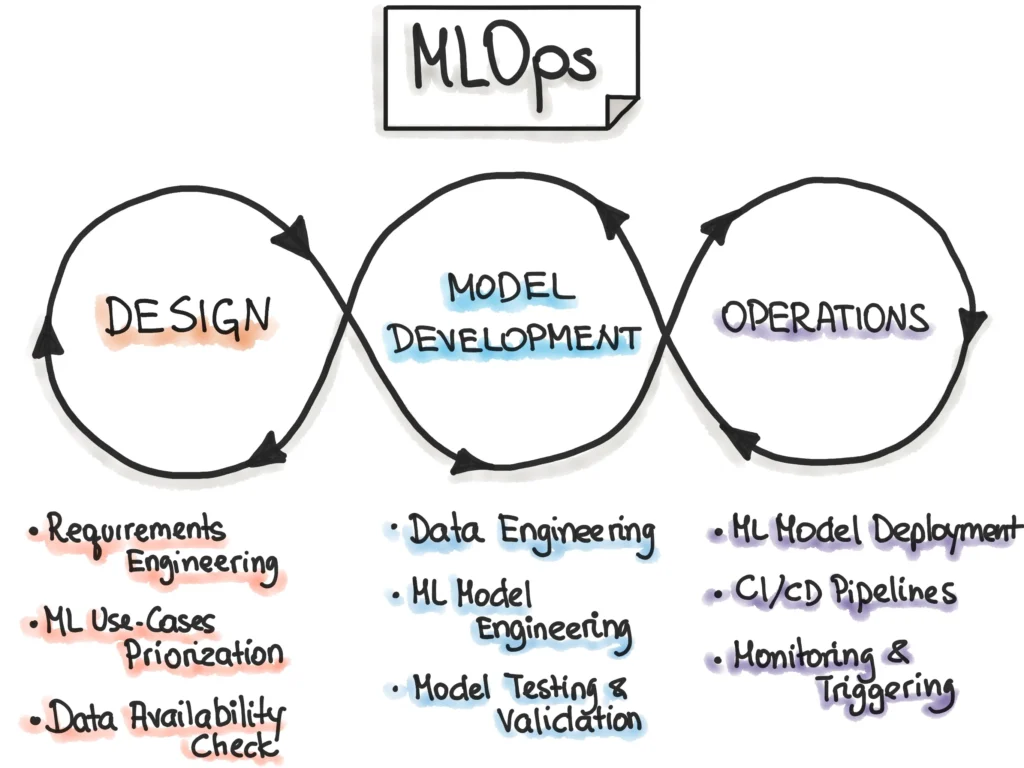
Contrairement aux logiciels classiques, un modèle dépend des variations des données réelles. Nous orchestrons ce phénomène sous la forme d’une boucle infinie, un peu comme un moteur bien réglé qui tourne sans s’arrêter.
- L’ingénierie des données : Collecter, nettoyer et suivre les modifications des jeux de données d’entraînement.
- Le développement du modèle : Tester des algorithmes et suivre les paramètres de recherche.
- L’automatisation CI/CD : Construire des pipelines pour valider le code, vérifier les données entrantes et empaqueter les modèles dans des conteneurs.
- Le déploiement et service (Serving) : Transférer le modèle finalisé vers le cloud ou des serveurs locaux afin de générer des prédictions en direct.
- La surveillance continue : Suivre les performances pour détecter la dérive des données.
DevOps contre MLOps : une divergence de trajectoire
Le MLOps s’inspire du DevOps mais ajoute une complexité majeure liée à la volatilité des données. Conduire un projet DevOps classique ressemble à rouler sur une route balisée, tandis que le MLOps exige de s’adapter à un terrain qui change de forme sous nos roues.
| Caractéristique | DevOps traditionnel | MLOps |
|---|---|---|
| Focus principal | Gestion du code et de l’infrastructure informatique. | Gestion conjointe du code, des données et des modèles. |
| Éléments versionnés | Code source et configurations applicatives. | Code, jeux de données massifs, paramètres et poids du modèle. |
| Besoins de surveillance | Disponibilité du système, latence et bogues de code. | Précision des prédictions, dérive des données et dégradation du modèle. |
| Nature du pipeline | Linéaire (Construction, Test, Déploiement). | Boucle (Déploiement, Surveillance, Réentraînement). |
Pourquoi franchir le pas ?
Le déploiement artisanal génère de la frustration.
Le MLOps élimine d’abord les modèles obsolètes qui restent bloqués sur l’ordinateur d’un scientifique de données faute de passerelle de production. Il réduit ensuite la dette technique en traçant chaque variable. Vous pouvez reproduire ou annuler n’importe quelle décision logicielle sans panique. Enfin, cette rigueur accélère la mise sur le marché. Vos ingénieurs déploient des mises à jour en quelques minutes au lieu de longs mois d’efforts manuels.
Les quatre piliers indispensables du MLOps
Pour garder les mains sur le volant et assurer la stabilité de nos systèmes, nous nous appuyons sur quatre fondations techniques.
- Le versionnage de code (Git) : Il conserve l’historique des scripts d’entraînement et des configurations.
- Le versionnage des données (DVC) : Il suit l’évolution des volumes massifs de données. Si un modèle fléchit, vous devez identifier le jeu de données exact utilisé lors de sa création.
- Le registre de modèles (Model Registry) : Une bibliothèque centrale pour stocker les modèles entraînés, documenter leurs performances et valider les autorisations de mise en production.
- Le magasin de fonctionnalités (Feature Store) : Une base de données partagée stockant les caractéristiques de données précalculées pour éviter les calculs redondants entre équipes.
L’échelle de maturité en trois niveaux
Votre entreprise évolue par étapes.
Le niveau 0 repose sur un processus manuel. Les scientifiques de données créent des modèles dans des cahiers d’expérimentation comme Jupyter. Ils livrent ensuite un fichier brut aux ingénieurs. Ce transfert artisanal engendre des lenteurs et des pannes fréquentes.
Le niveau 1 introduit l’automatisation du pipeline d’entraînement. À l’arrivée de nouvelles données, le système relance l’entraînement de manière autonome. Le réentraînement continu protège le modèle contre l’obsolescence.
Le niveau 2 atteint l’automatisation complète CI/CD. Une modification du code d’entraînement déclenche des tests, reconstruit le pipeline, valide la sécurité et déploie le résultat. C’est l’approche idéale pour gérer des milliers de modèles actifs sans risque.
Cas concret : l’application de VTC
Visualisons le parcours d’une mise à jour de tarif lors d’une perturbation climatique.
[Données trafic & météo]
│
▼
[Pipeline de réentraînement] ───> [Validation de qualité] ───> [Déploiement progressif (Canary)]
│
▼
[Surveillance fantôme]
│
▼
[Alerte de dérive]
Une tempête s’abat sur la ville. Le trafic ralentit. Les prévisions tarifaires perdent leur justesse. Le système détecte cette baisse de précision. Le pipeline de réentraînement s’active avec les données climatiques fraîches. Avant la mise en ligne, le nouveau modèle subit un test strict. Il doit prouver sa supériorité face à l’ancien algorithme et garantir l’absence de biais. Enfin, le déploiement s’effectue via une méthode progressive. Nous ciblons un pour cent des utilisateurs pour tester la stabilité du système avant de l’étendre à toute la flotte.
La dégradation du modèle : le tueur silencieux
Un logiciel classique s’arrête net avec une erreur visible. Un modèle d’apprentissage automatique échoue en silence. Son code tourne, mais ses prédictions perdent tout leur sens sous l’effet de deux phénomènes précis.
D’un côté, nous subissons la dérive des données (Data Drift). Les entrées réelles ne ressemblent plus aux données d’entraînement. Pensez à un outil de détection des fraudes conçu avant la pandémie de 2020. Le changement des habitudes d’achat en ligne a rendu ses analyses obsolètes. De l’autre côté se trouve la dérive de concept (Concept Drift). Les propriétés statistiques de la cible changent. Par exemple, une hausse des taux d’intérêt modifie le prix qu’un acheteur accepte de payer pour une maison, même si le bien immobilier reste inchangé.
L’architecture technique du MLOps moderne
Pour contrer ces dérives, nous construisons un écosystème d’outils spécialisés.
Orchestration : Kubeflow / Apache Airflow │ ▼ Suivi et Stockage : MLflow / Weights & Biases / DVC │ ▼ Déploiement et Surveillance : BentoML / Evidently AI
L’orchestration coordonne les étapes de nos pipelines grâce à des outils comme Kubeflow ou Apache Airflow. Pour consigner nos expériences, nous utilisons MLflow ou Weights & Biases. Ces plateformes enregistrent les hyperparamètres et les courbes de perte. Le stockage des données s’appuie sur DVC pour capturer des instantanés de volumes massifs sans ralentir Git. Pour servir nos modèles, BentoML ou Triton Inference Server convertissent les fichiers en points d’accès API rapides. Enfin, la surveillance de l’état du système incombe à des outils de vigilance comme Evidently AI ou Whylogs pour détecter la dérive dès son apparition.
Gouvernance globale et conformité éthique
La dernière couche concerne la responsabilité légale, cruciale dans la santé ou la finance.
Le suivi de l’historique (Lineage Tracking) permet de remonter le temps. Nous pouvons relier une prédiction faite aujourd’hui au jeu de données exact et au code d’entraînement utilisés six mois plus tôt. L’audit des biais garantit quant à lui l’équité de nos systèmes. Nos pipelines évaluent les modèles pour proscrire toute discrimination liée à l’âge, au genre ou à l’origine avant la mise en service.