Imaginez un interlocuteur brillant mais amnésique. À chaque fois que vous clignez des yeux, il oublie votre existence. C’est le quotidien des grands modèles de langage (LLM). Pour bâtir des applications fluides, nous devons maîtriser l’art du contexte.
Le contexte désigne l’ensemble des informations fournies au modèle lors d’une requête unique pour guider sa réponse. Les LLM fonctionnent de façon stateless, sans mémoire persistante d’une interaction à l’autre. Chaque historique, consigne ou donnée doit être réinjecté dans le prompt à chaque nouvel appel d’API.
La mémoire d’un LLM n’existe que le temps d’un calcul unique.
Les piliers du contexte (context window)
Pour structurer une requête riche, nous assemblons différentes couches de données :
- Directives système : Règles fondamentales définissant la personnalité, le ton, la sécurité et le format attendu.
- Historique de discussion : Copie des échanges précédents insérée pour maintenir le fil de la conversation.
- Connaissances externes : Données extraites en temps réel de documents ou de bases de données grâce au RAG.
- Résultats d’outils : Retours d’API ou de code que le modèle doit analyser pour finaliser sa tâche.
La fenêtre de contexte en détails
Cette fenêtre définit la limite physique de travail d’un modèle, mesurée en jetons (tokens).
| Concept | Définition | Caractéristiques |
| Capacité en jetons | Unité de mesure du texte (environ 4 caractères par jeton). | Varie de 4 000 jetons à plus d’un million pour les architectures récentes. |
| Coût de calcul | Ressources nécessaires au traitement des données. | L’architecture Transformer de base exige une puissance qui évolue de manière quadratique avec la longueur du texte. |
| Troncation sans état | Comportement du système en cas de dépassement de la limite. | Les données excédentaires sont coupées ou résumées pour éviter un blocage de l’API. |
Les pièges du grand format
Une grande fenêtre de contexte fait rêver. Pourtant, la réalité technique impose des contraintes opérationnelles majeures.
Le phénomène de perte d’attention au centre (“Lost in the Middle“) en est la preuve. Les chercheurs de l’université de Stanford ont mis en lumière une faille. Les modèles affichent une bonne capacité de récupération pour les informations placées au début ou à la fin du prompt. Les données enfouies au milieu du texte subissent une baisse d’attention, le taux de réussite chutant sous la barre des 50 %.
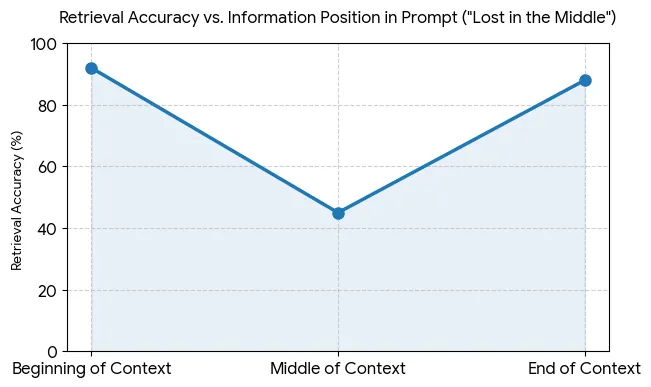
La dilution de l’attention dégrade la pertinence globale. Un trop-plein d’informations inutiles favorise l’apparition d’hallucinations.
Le traitement de volumes massifs augmente le délai de réponse et fait grimper les coûts d’exploitation des API.
Sous le capot : le traitement de l’information
Le modèle ne lit pas le texte mot à mot. Il analyse l’ensemble des jetons en même temps via un mécanisme d’attention.
Il calcule des poids mathématiques pour lier chaque jeton aux autres. Le sens du mot “prise” change selon la présence des mots “courant” ou “décision” dans l’environnement lexical.
Le partage de la ressource
La fenêtre de contexte est un réservoir partagé entre l’entrée (le prompt) et la sortie (la réponse). Si votre limite est de 8 000 jetons et que votre prompt en consomme 7 000, la réponse ne pourra pas dépasser 1 000 jetons sous peine d’interruption brute. De plus, traiter les jetons d’entrée coûte moins cher que de générer des jetons de sortie, mais les volumes massifs alourdissent les factures.
La mécanique mathématique de l’attention
Pour aller plus loin, analysons le moteur de l’architecture Transformer. Le mécanisme d’attention, génère trois vecteurs pour chaque jeton : les requêtes (Q), les clés (K) et les valeurs (V).
La formule centrale s’écrit ainsi :
Attention(Q, K, V) = softmax((Q * K^T) / sqrt(d_k)) * VLe goulot d’étranglement provient du produit matriciel entre Q et la transposée de K. Pour une séquence de longueur N, le modèle manipule une matrice de taille N x N. Doubler la longueur du texte multiplie par quatre les besoins en puissance de calcul et en mémoire vidéo (VRAM). C’est la complexité quadratique O(N²).
Les stratégies de gestion pour les ingénieurs
Pour contourner ces barrières physiques, les développeurs déploient des architectures spécifiques :
- Mise en cache KV (Key-Value Caching) : Cette technique stocke les matrices K et V des échanges passés dans la mémoire du GPU. Lors des tours de parole suivants, le modèle ne calcule que les poids des nouveaux jetons.
- Génération augmentée par récupération (RAG) : Au lieu d’injecter un livre complet, le système recherche les extraits pertinents et ne transmet que ces passages au modèle.
- Fenêtres glissantes : Cette méthode supprime les messages les plus anciens pour respecter la limite matérielle.
- Mémoire par résumé : Un LLM condense l’historique ancien pour ne conserver qu’un paragraphe de synthèse.
- Découpage en blocs (Chunking) : Des techniques comme le Map-Reduce permettent de traiter des documents segmentés avant d’en faire la synthèse finale.
- Ring Attention et Chunked Prefill : Cette approche distribue le calcul de la matrice d’attention sur plusieurs puces graphiques connectées en anneau pour repousser les limites physiques.
Ces avancées permettent d’atteindre des fenêtres de plusieurs millions de jetons tout en optimisant l’usage de la mémoire matérielle.