L’apprentissage automatique transforme le monde. J’observe son impact partout. Ce domaine, une branche de l’intelligence artificielle, permet aux systèmes informatiques d’apprendre. Ils s’améliorent grâce aux données. Ils n’ont pas besoin d’une programmation explicite pour chaque tâche. Au lieu de suivre des règles rigides, ces systèmes utilisent des algorithmes statistiques. Ils identifient des motifs. Ils créent des modèles mathématiques. Ces modèles prédisent ou décident sur de nouvelles données. C’est fascinant.
L’apprentissage automatique : une définition simple
Au fond, l’apprentissage automatique, c’est cela : enseigner à un ordinateur. Il doit reconnaître des motifs dans les données. Ainsi, il peut prendre des décisions seul. Il peut faire des prédictions. Aucun humain n’écrit de programme spécifique pour chaque tâche. C’est une idée puissante.
Imaginez que vous enseignez à un enfant à identifier un fruit. C’est une bonne analogie.
- L’ancienne méthode (Programmation Traditionnelle) : Vous donnez à l’ordinateur une liste de règles strictes. “Si c’est rouge, rond, et a une tige, c’est une pomme.” Si l’ordinateur voit une pomme verte, il échoue. Elle ne correspond pas à la règle exacte.
- La méthode de l’Apprentissage Automatique : Vous montrez à l’ordinateur des milliers de photos de pommes. L’ordinateur “apprend” les motifs d’une pomme. Il voit différentes couleurs, formes, tailles. Quand vous lui montrez une nouvelle photo, il dit correctement : “C’est une pomme.” C’est l’intelligence en action.
Comprendre le cœur de l’apprentissage automatique
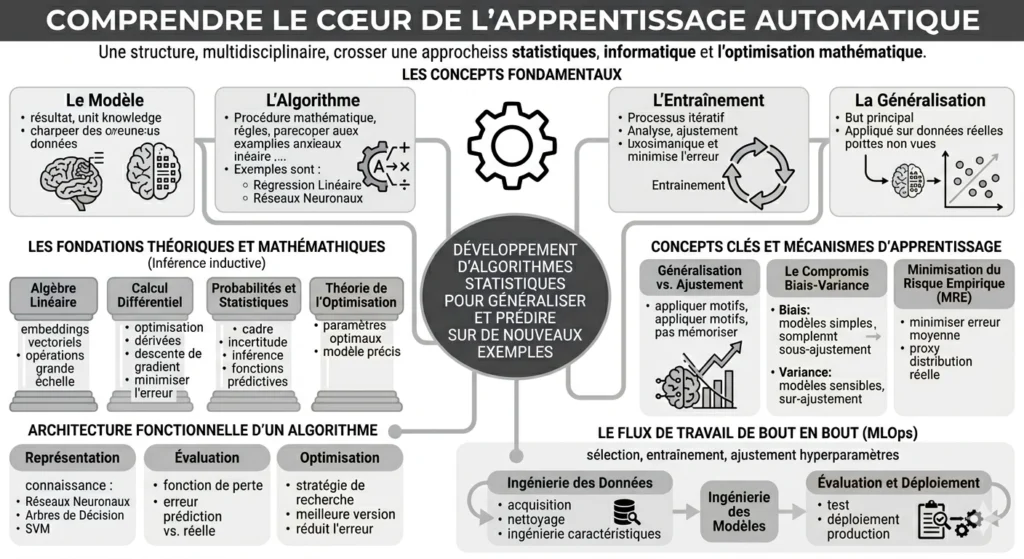
Plus en profondeur, l’apprentissage automatique est un champ multidisciplinaire. Il croise les statistiques, l’informatique, et l’optimisation mathématique. Il se concentre sur le développement d’algorithmes statistiques. Ces algorithmes généralisent à partir de données limitées. Ils font des prédictions précises sur de nouveaux exemples. Des exemples que le système n’a jamais vus. C’est un défi constant.
Les concepts fondamentaux
- Le Modèle : C’est le résultat d’un algorithme d’apprentissage automatique. Il est formé sur un jeu de données. Il représente la “connaissance” acquise par le système. C’est son savoir.
- L’Algorithme : C’est la procédure mathématique spécifique. C’est l’ensemble de règles. Il traite les données et construit le modèle. La régression linéaire ou les réseaux neuronaux en sont des exemples.
- L’Entraînement : C’est un processus itératif. L’algorithme analyse les données. Il ajuste ses paramètres internes. Il vise à minimiser les erreurs. C’est le travail du modèle.
- La Généralisation : C’est le but principal de l’apprentissage automatique. C’est la capacité d’un modèle entraîné à fonctionner précisément. Il s’applique sur de nouvelles données du monde réel. Des données non vues pendant l’entraînement.
Les fondations théoriques et mathématiques
L’apprentissage automatique est fondamentalement un processus d’inférence inductive. Il repose sur quatre piliers mathématiques essentiels.
- L’Algèbre Linéaire : Elle sert à représenter les points de données. On les voit comme des embeddings vectoriels. Elle réalise des opérations à grande échelle sur des ensembles de données multidimensionnels.
- Le Calcul Différentiel : Il est crucial pour l’optimisation. Il utilise les dérivées dans la descente de gradient. Il minimise l’erreur de manière itérative.
- Les Probabilités et les Statistiques : Elles fournissent le cadre. Elles modélisent l’incertitude. Elles utilisent l’inférence. Le but est de trouver des fonctions prédictives.
- La Théorie de l’Optimisation : Elle se concentre sur la recherche des paramètres optimaux. Ceux-ci aboutissent au comportement de modèle le plus précis.
Architecture fonctionnelle d’un algorithme d’apprentissage automatique
Chaque algorithme d’apprentissage automatique possède trois composants essentiels. C’est la base de tout.
- La Représentation : C’est la façon dont la connaissance s’exprime. Pensez aux réseaux neuronaux, aux arbres de décision, ou aux machines à vecteurs de support.
- L’Évaluation : Une fonction de perte (fonction d’erreur) mesure la différence. Elle compare la prédiction du modèle à la valeur réelle.
- L’Optimisation : Le processus de recherche ou la stratégie est utilisé. Il trouve la meilleure version du modèle. Il réduit l’erreur mesurée.
Concepts clés et mécanismes d’apprentissage
- Généralisation vs. Ajustement : Le but principal est la généralisation. C’est la capacité d’appliquer des motifs appris à de nouvelles données. Ce n’est pas juste mémoriser des exemples d’entraînement.
- Le Compromis Biais-Variance : C’est un défi fondamental dans la sélection de modèle. Le biais fait référence aux erreurs. Elles viennent de modèles trop simples (sous-ajustement). La variance concerne les erreurs des modèles trop sensibles aux petites fluctuations des données d’entraînement (sur-ajustement).
- Minimisation du Risque Empirique (MRE) : C’est un principe d’induction. L’algorithme tente de minimiser l’erreur moyenne. Il agit sur l’ensemble de données d’entraînement connu. Il sert de proxy pour la distribution réelle inconnue.
Le flux de travail de bout en bout
L’implémentation industrielle de l’apprentissage automatique suit un cycle de vie systématique. Il est souvent géré via MLOps. C’est notre feuille de route.
- Ingénierie des Données : Acquisition des données, nettoyage pour supprimer les valeurs aberrantes, et ingénierie des caractéristiques. Elle transforme les données brutes en entrées numériques utilisables.
- Ingénierie des Modèles : Sélection d’un algorithme, entraînement du modèle, et ajustement des hyperparamètres. Il optimise l’architecture.
- Évaluation et Déploiement : Test du modèle contre des ensembles de données séparés. Le modèle est ensuite déployé en production.
Les grands types d’apprentissage automatique
L’apprentissage automatique se catégorise généralement. Il dépend de la manière dont le système apprend. C’est assez clair.
- Apprentissage Supervisé : Le modèle s’entraîne sur des données “étiquetées”. Les bonnes réponses sont fournies. Il sert principalement à la classification (par exemple, identifier les spams) et à la régression (par exemple, prédire le prix des maisons).
- Apprentissage Non Supervisé : Le modèle analyse des données non étiquetées. Il trouve des structures ou des motifs cachés par lui-même. Les utilisations courantes incluent le clustering (regrouper des clients similaires) et la détection d’anomalies (repérer les transactions frauduleuses).
- Apprentissage par Renforcement : Un “agent” apprend à prendre des décisions. Il procède par essais et erreurs. Il interagit avec un environnement. Il maximise une récompense. C’est fréquent en robotique et dans les jeux.
- Apprentissage Semi-Supervisé : Cette approche hybride utilise une petite quantité de données étiquetées. Elles guident le processus d’apprentissage. Un volume beaucoup plus grand de données non étiquetées est aussi utilisé.
Je pense à Spotify. C’est un excellent exemple réel. Les trois types d’apprentissage automatique travaillent ensemble.
- Apprentissage Supervisé : Recommandations de Chansons. Spotify utilise votre historique explicite (chansons aimées ou ajoutées aux listes de lecture). Il prédit ce que vous apprécierez d’autre. C’est “supervisé”. Les données sont étiquetées : “L’utilisateur a aimé cette chanson ; trouvez-en une autre similaire.”
- Apprentissage Non Supervisé : “Découvertes de la Semaine”. L’application utilise des algorithmes de clustering. Ils regroupent les chansons. Les caractéristiques audio comme le tempo, le rythme, la mélodie sont analysées. Le système analyse des milliards de listes de lecture créées par d’autres utilisateurs. Il voit quelles chansons sont souvent regroupées. Il n’a pas besoin d’un humain pour les étiqueter. Il trouve ces connexions cachées seul. C’est magique.
- Apprentissage par Renforcement : Personnalisation de l’Écran d’Accueil. L’écran d’accueil utilise les essais et erreurs. Il maximise votre satisfaction à long terme. S’il vous montre un nouveau podcast et que vous l’écoutez en boucle, l'”agent” reçoit une récompense. Il apprend à afficher un contenu similaire. Si vous le passez immédiatement, il reçoit une “pénalité”. Il ajuste sa stratégie pour la prochaine fois.
D’autres applications que vous utilisez probablement intègrent aussi l’apprentissage automatique.
- Uber : Il utilise l’apprentissage par renforcement. Il équilibre l’offre de chauffeurs avec la demande des passagers en temps réel. Il réduit les temps d’attente. Il optimise les revenus des chauffeurs.
- Netflix : Il utilise l’apprentissage supervisé. Il analyse votre historique de visionnage. Il prédit quelles miniatures vous inciteront le plus à cliquer sur un titre.
- Gmail : Il utilise l’apprentissage supervisé. C’est pour son filtre anti-spam. Il est entraîné sur des millions d’e-mails étiquetés comme “spam” ou “non-spam” par les utilisateurs.
Apprentissage automatique vs. Apprentissage profond
Ces termes sont souvent interchangeables. Mais l’apprentissage profond est un sous-ensemble spécialisé de l’apprentissage automatique. C’est une distinction importante. Il utilise des réseaux neuronaux artificiels “profonds”. Ils ont de nombreuses couches. Ils apprennent automatiquement des caractéristiques complexes. Ces caractéristiques proviennent de données brutes. Pensez aux images ou à la parole. L’apprentissage automatique traditionnel, lui, demande souvent aux humains de sélectionner manuellement les caractéristiques. Celles sur lesquelles l’ordinateur doit se concentrer. C’est la principale différence.
Les types avancés d’apprentissage automatique
Au-delà des trois catégories primaires, l’apprentissage automatique comprend plusieurs paradigmes avancés. Ils sont conçus pour gérer des défis de données complexes. Coûts d’étiquetage élevés, problèmes de confidentialité, ou besoin d’apprendre avec très peu d’informations. Voici les cinq types avancés les plus reconnus.
- Apprentissage Auto-Supervisé (SSL) : Il permet aux modèles de s’entraîner sur des données non étiquetées. Il crée ses propres “pseudo-étiquettes” à partir des données elles-mêmes. C’est courant en traitement du langage naturel (NLP) et en vision par ordinateur. L’étiquetage manuel de vastes jeux de données est trop coûteux.
- Comment ça marche : Le modèle cache une partie des données. C’est comme un mot dans une phrase. Il essaie de le prédire en utilisant le reste de l’information.
- Apprentissage Semi-Supervisé : Cette approche fait le pont entre l’apprentissage supervisé et non supervisé. Elle utilise une petite quantité de données étiquetées. Elle la combine avec une grande quantité de données non étiquetées.
- Comment ça marche : Le petit ensemble étiqueté fournit un “guide” ou une base de référence. Le modèle l’utilise ensuite pour donner un sens à l’immense pool non étiqueté. C’est très efficace en imagerie médicale. Les données étiquetées par des experts sont rares.
- Apprentissage par Transfert : Cela implique de prendre un modèle déjà entraîné sur une tâche. On le réutilise pour une tâche différente, mais liée.
- Comment ça marche : Un modèle pourrait être entraîné à reconnaître des millions d’objets généraux. Vous “transférez” ensuite sa connaissance des formes et textures de base. Cela l’aide à identifier des types spécifiques de tumeurs médicales. Cela demande très peu d’entraînement additionnel.
- Apprentissage Fédéré : C’est une méthode d’apprentissage distribué. Elle est conçue pour la confidentialité.
- Comment ça marche : Au lieu de déplacer des données sensibles vers un serveur central, le modèle est envoyé à des appareils individuels. Votre smartphone en est un exemple. Il s’entraîne localement sur vos données. Seules les “améliorations” résultantes du modèle sont renvoyées au serveur central. Elles mettent à jour la version globale.
- Méta-Apprentissage (“Apprendre à Apprendre”) : Le méta-apprentissage se concentre sur l’entraînement de modèles capables de s’adapter rapidement. Ils s’adaptent à de nouvelles tâches avec un minimum de données. C’est souvent appelé apprentissage “few-shot” ou “zero-shot”.
- Comment ça marche : Le modèle est entraîné sur une grande variété de tâches. Ainsi, il apprend le processus d’apprentissage. Cela lui permet de reconnaître un nouvel animal qu’il n’a jamais vu auparavant. Il le fait après avoir vu juste un ou deux exemples. C’est l’essence de l’adaptabilité.
Comment fonctionne l’apprentissage automatique
L’apprentissage automatique fonctionne de manière systématique. C’est un processus itératif. Il transforme des données brutes en un modèle mathématique. Ce modèle peut faire des prédictions ou des décisions seul.
Le mécanisme central
La programmation traditionnelle fonctionne ainsi : l’humain écrit des règles spécifiques (Entrée + Règles = Sortie). L’apprentissage automatique inverse cela. L’ordinateur reçoit des entrées et des sorties historiques. Il doit découvrir les motifs sous-jacents (Entrée + Sortie = Règles). C’est une révolution.
Le flux de travail étape par étape
Chaque projet d’apprentissage automatique suit généralement ces étapes. C’est une approche éprouvée.
- Collecte et Préparation des Données : C’est souvent l’étape la plus longue. Elle implique de rassembler des données. Les sources sont variées : API, bases de données, ou web scraping. Il faut les nettoyer. Supprimer les erreurs, les doublons, les valeurs manquantes.
- Ingénierie des Caractéristiques : Les data scientists sélectionnent les “caractéristiques” les plus pertinentes. Ce sont les attributs des données. Le modèle doit se concentrer sur elles. Pour prédire les prix des maisons, les caractéristiques peuvent inclure la superficie et le nombre de chambres.
- Entraînement du Modèle : Un algorithme (réseau neuronal ou arbre de décision) reçoit une grande partie des données. C’est l'”ensemble d’entraînement”. Pendant cette phase, le modèle ajuste ses paramètres mathématiques internes. Il minimise la différence entre ses prédictions et les résultats historiques réels.
- Évaluation et Ajustement : Le modèle entraîné est testé sur un “ensemble de test” séparé. Il n’a jamais vu ces données. On vérifie sa précision. Si les performances sont médiocres, les développeurs “ajustent” les réglages du modèle (hyperparamètres). Ils le réentraînent.
- Déploiement et Surveillance : Une fois suffisamment précis, le modèle est lancé. Il opère dans un environnement réel. Il fait des prédictions en direct. Il doit être surveillé en permanence. La “dérive” est une préoccupation. C’est lorsque sa précision diminue. Les motifs des données réelles ont changé avec le temps.
Composants techniques clés
- Fonction de Perte : Une formule mathématique mesure la “mauvaise” qualité des prédictions du modèle.
- Optimisation : Des techniques comme la descente de gradient sont utilisées pendant l’entraînement. Elles ajustent systématiquement le modèle. Elles réduisent cette erreur.
- Généralisation : C’est le but ultime. S’assurer que le modèle ne mémorise pas seulement les données d’entraînement. Il doit fonctionner correctement sur de nouvelles informations. Des informations jamais vues.
L’IA et l’apprentissage automatique : quelle est la différence ?
Pensez à une relation de “poupées russes”. L’Intelligence Artificielle (IA) est la grande poupée extérieure. L’Apprentissage Automatique (AA) est une poupée plus petite. Elle s’insère à l’intérieur. C’est une image claire.
La comparaison
- IA (La Vue d’Ensemble) : C’est le concept large. Créer des machines qui simulent l’intelligence humaine. Cela inclut tout. D’un simple programme “si-alors” (comme un thermostat de base) à des systèmes complexes. Ils peuvent “raisonner”, “planifier”, ou “comprendre” le langage. C’est le rêve de l’humanité.
- AA (La Méthode Spécifique) : Une manière spécifique d’atteindre l’IA. Au lieu qu’un humain écrive des règles pour chaque scénario, nous donnons des données à l’ordinateur. Il découvre les règles par lui-même.
Différences clés en un coup d’œil
| Caractéristique | Intelligence Artificielle (IA) | Apprentissage Automatique (AA) |
|---|---|---|
| Définition | La science vaste de l’imitation des capacités humaines. | Un sous-ensemble de l’IA axé sur l’apprentissage à partir de données. |
| Objectif | Construire un système “intelligent” capable de résoudre des tâches. | Construire un modèle qui améliore ses performances avec le temps. |
| Logique | Peut être basée sur des règles “dures” ou des motifs appris. | Toujours basée sur des motifs statistiques et des données. |
| Succès | Le succès se définit par la qualité de l’imitation d’une tâche. | Le succès se définit par la précision et l’erreur minimale. |
Une analogie : apprendre à jouer aux échecs
- IA : Un programme informatique. Il connaît chaque mouvement légal possible. Il suit un “arbre” de règles. Un grand maître les a écrites. Il choisit le meilleur coup. C’est la force brute.
- AA : Un programme informatique. Il regarde 10 millions de parties d’échecs. Il découvre quels coups mènent à la victoire. Il développe sa propre stratégie. Elle se base sur ce qu’il a vu. C’est l’expérience.
En bref : Tout l’Apprentissage Automatique est de l’IA, mais toute l’IA n’est pas de l’Apprentissage Automatique.
ChatGPT : est-ce de l’IA ou de l’apprentissage automatique ?
ChatGPT est les deux. C’est une application d’intelligence artificielle. Elle est construite avec des techniques d’apprentissage automatique. C’est une symbiose parfaite.
Pour comprendre comment ils s’imbriquent, examinez la hiérarchie de la technologie.
- Intelligence Artificielle (IA) : C’est le grand objectif “parapluie”. ChatGPT est considéré comme de l’IA. Il effectue des tâches. Ces tâches nécessitent généralement l’intelligence humaine. Comprendre le langage et résoudre des problèmes en sont des exemples.
- Apprentissage Automatique (AA) : C’est le “moteur” spécifique. ChatGPT est de l’apprentissage automatique. On ne lui a pas donné une liste de règles pour parler. Il a été entraîné. Il a utilisé des ensembles de données massifs. Il identifie les motifs. Il prédit le mot le plus probable dans une phrase.
- Apprentissage Profond (DL) : C’est un sous-ensemble spécialisé de l’apprentissage automatique. ChatGPT l’utilise spécifiquement. Il repose sur des “réseaux neuronaux” complexes. Ils ont de nombreuses couches (l’architecture Transformer). Ils traitent des milliards de points de données. C’est la magie derrière la conversation.
En résumé : ChatGPT est une application d’IA créée à l’aide de méthodes d’apprentissage automatique.
Découvrez — Le Projet Stargate AI : Chiffres, Faits, et Tout ce que Vous Devez Savoir
À quoi sert l’apprentissage automatique ?
L’apprentissage automatique sert à automatiser des tâches complexes. Il découvre des motifs cachés dans de grands ensembles de données. Il fait des prédictions précises. Là où la programmation humaine traditionnelle est trop lente ou rigide. C’est son grand pouvoir.
Applications courantes par secteur
- Santé : Les modèles d’apprentissage automatique analysent les scans médicaux (rayons X, IRM). Ils détectent des maladies comme le cancer ou la pneumonie. Ils le font plus tôt que les médecins humains. Il accélère également la découverte de médicaments. Il prédit comment différents composés interagiront.
- Finance et Banque : Les banques utilisent l’apprentissage automatique. C’est pour la détection de fraude en temps réel. Il identifie les schémas de dépenses inhabituels. Il alimente également la notation de crédit. Il permet le trading algorithmique automatisé en bourse.
- Commerce de Détail et E-commerce : Des plateformes comme Amazon et Netflix utilisent des moteurs de recommandation. Ils suggèrent des produits et du contenu. Ils sont adaptés au comportement individuel de l’utilisateur. Les détaillants appliquent aussi l’apprentissage automatique. C’est pour la prévision de la demande. Cela optimise les niveaux de stock.
- Transport : Les véhicules autonomes dépendent de l’apprentissage automatique et de la vision par ordinateur. Ils naviguent. Ils prennent des décisions en une fraction de seconde. Des applications comme Google Maps l’utilisent. C’est pour prédire les conditions de circulation. Ils suggèrent les itinéraires les plus rapides.
- Fabrication : Les “usines intelligentes” utilisent la maintenance prédictive. Elles identifient les pannes d’équipement potentielles. Elles les trouvent avant qu’elles ne se produisent. Cela réduit considérablement les temps d’arrêt. C’est une économie massive.
Utilisations personnelles quotidiennes
- Assistants Virtuels : Siri, Alexa et Google Assistant utilisent le traitement du langage naturel (NLP). Ils comprennent et répondent aux commandes vocales.
- Filtrage d’E-mails : Des services comme Gmail trient automatiquement les e-mails. Ils filtrent les spams. Ils utilisent des algorithmes de classification de texte.
- Médias Sociaux : Des plateformes comme Instagram et LinkedIn utilisent l’apprentissage automatique. Ils organisent des fils d’actualité personnalisés. Ils suggèrent de nouvelles connexions. Ils se basent sur vos interactions. C’est très astucieux.
Comment apprendre l’apprentissage automatique
Apprendre l’apprentissage automatique (AA) exige un mélange équilibré. Il faut de la programmation, des mathématiques, et des projets pratiques. Une feuille de route courante existe. Les débutants et les experts l’utilisent. Elle implique de construire des bases solides en Python. Il faut comprendre les concepts mathématiques essentiels. Il faut aussi réaliser des projets de bout en bout. C’est un chemin bien tracé.
Étape 1 : Fondations en programmation
Maîtriser Python est la première étape. Elle est cruciale. Concentrez-vous sur ces domaines.
- Python de base : Types de données, boucles, conditionnels et fonctions.
- Bibliothèques de données : Apprenez NumPy (pour le calcul scientifique) et Pandas (pour la manipulation de données).
- Visualisation : Utilisez Matplotlib ou Seaborn. Vous visualiserez vos données.
Étape 2 : Mathématiques essentielles
Pas besoin d’être un expert en mathématiques. Mais comprendre ces trois piliers est vital. Vous déboguerez et améliorerez les modèles. Croyez-moi.
- Algèbre Linéaire : C’est le “langage” de l’apprentissage automatique. Il représente les données comme des matrices et des vecteurs.
- Calcul Différentiel : Spécifiquement les dérivées et les gradients. Ils aident les algorithmes à “apprendre”. Ils minimisent les erreurs via la descente de gradient.
- Statistiques et Probabilités : Cruciales pour donner un sens aux données. Et gérer l’incertitude.
Étape 3 : Théorie et algorithmes d’apprentissage automatique
Commencez par des cours structurés de haute qualité. Apprenez les algorithmes de base. La régression linéaire, les arbres de décision, et le clustering en font partie.
- Cours Recommandés :
- Machine Learning Specialization (Andrew Ng/Coursera) – Idéal pour les fondations.
- Google ML Crash Course – Gratuit et très interactif.
- Practical Deep Learning for Coders (fast.ai) – Excellent pour une approche pratique.
Étape 4 : Construire un portfolio
Appliquer ses connaissances aux données du monde réel est la meilleure façon de solidifier ses compétences. C’est l’étape clé.
- Projets pour débutants : Prédiction de survie du Titanic, prévision du prix des maisons, et classificateurs de spam par e-mail.
- Conseil Avancé : Évitez de n’utiliser que des jeux de données propres. Ceux de Kaggle par exemple. Essayez de scraper vos propres données. Utilisez des API publiques. Montrez que vous pouvez gérer des informations réelles, parfois désordonnées.
Étape 5 : Spécialiser (Optionnel)
Une fois les bases solides, vous pouvez plonger dans des domaines. Le Traitement du Langage Naturel (NLP), la Vision par Ordinateur, ou le MLOps. C’est le déploiement de modèles en production. Le monde vous attend.
Chez DeepLearn Academy, nous proposons des parcours personnalisés en e-learning et intra. Vous apprendrez l’apprentissage automatique. Découvrez nos formations !
Livres pour apprendre l’apprentissage automatique
Pour apprendre l’apprentissage automatique en 2026, le meilleur livre dépend de votre point de départ. Vous voulez une introduction “sans maths” ? Un guide de codage pratique ? Ou une plongée théorique profonde ? Chaque profil a son livre.
Idéal pour le codage pratique
Si vous voulez commencer à construire des modèles immédiatement avec Python, voici les standards de l’industrie.
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (3e édition) par Aurélien Géron. C’est la “Bible” de l’apprentissage automatique pratique. Il utilise une approche basée sur des projets. Il enseigne tout. De la régression de base aux modèles de transformateurs avancés.
- Machine Learning with Python, TensorFlow and Scikit-Learn (Édition 2026) par Jerry E. Riddick. Un guide frais et moderne. Spécifiquement mis à jour. Il couvre les derniers outils de l’industrie et le développement de l’IA dans le monde réel.
- Python Machine Learning By Example (4e édition) par Yuxi (Hayden) Liu. Ce livre se concentre sur les meilleures pratiques. Il inclut du contenu mis à jour sur les transformateurs NLP et les modèles multimodaux.
Tendance LLM — Gemma 4 : Décryptage Complet & Guide pour Déployer et Maîtriser l’IA Open-Weight
Idéal pour les débutants absolus
Si vous n’avez aucune expérience préalable en codage ou en mathématiques, commencez ici.
- Machine Learning for Absolute Beginners (3e édition) par Oliver Theobald. Ce livre utilise un langage simple. Il propose des exemples visuels. Il évite les équations denses. C’est une excellente alternative aux manuels pour ceux qui vivent leur “moment Roi Lion” dans le domaine.
- Machine Learning For Dummies par John Paul Mueller et Luca Massaron. Un point d’entrée direct. Il couvre les concepts de base. Il aborde le codage R et Python. Il parle aussi du prétraitement des données.
Idéal pour les fondations mathématiques
Pour comprendre pourquoi les algorithmes fonctionnent, ces livres font le pont. Ils lient la théorie à l’application.
- Mathematics for Machine Learning par Marc Peter Deisenroth, A. Aldo Faisal, et Cheng Soon Ong. Un texte autonome. Il introduit l’algèbre linéaire, le calcul différentiel, et les probabilités. Spécifiquement dans le contexte de l’apprentissage automatique.
- Mathematics of Machine Learning par Tivadar Danka. Sorti en 2025. Il enseigne les mathématiques essentielles. Il le fait à travers des exemples Python pratiques. Idéal pour les ingénieurs. Ils apprennent mieux en faisant.
Références avancées et théoriques
Pour ceux qui cherchent à maîtriser les racines statistiques profondes du domaine, ces ouvrages sont incontournables.
- Machine Learning: A Probabilistic Perspective par Kevin Murphy. Une référence encyclopédique. Il utilise une approche probabiliste unifiée. Il couvre tout. Des modèles graphiques à l’apprentissage profond.
- The Elements of Statistical Learning (ESL). Un classique. Une “perspective de statisticien” sur l’apprentissage automatique. Certains le trouvent moins “moderne”. D’autres livres se concentrent plus sur l’informatique. Mais il reste l’étalon-or pour la théorie statistique fondamentale.
Vous souhaitez aller plus loin et approfondir vos connaissances en apprentissage automatique ? Poursuivez la lecture de cet article : ceci n’en est que la surface!
L’Épopée du Machine Learning : Mon Voyage à travers l’Intelligence des Machines
Je vois le machine learning (ML) comme une révolution silencieuse. Il a transformé des théories mathématiques en systèmes concrets. Aujourd’hui, il pilote notre monde moderne. Cette discipline, née de l’intelligence artificielle, a vite trouvé sa voie. Elle s’est concentrée sur les statistiques et la résolution de problèmes pratiques. C’est fascinant de voir son évolution.
Les Premières Étincelles (Années 1940-1950)
Les racines du ML sont profondes. Elles plongent dans la neurobiologie et l’informatique naissante.
- 1943 : L’Origine des Réseaux Neuronaux. Warren McCulloch et Walter Pitts ont créé un modèle mathématique. Il montrait que des neurones biologiques pouvaient être simulés par des circuits. Une idée brillante.
- 1949 : L’Apprentissage Hebbien. Donald Hebb a proposé une idée clé dans son ouvrage. Les voies neuronales se renforcent avec l’usage. Ce principe est fondamental pour l’entraînement des réseaux artificiels.
- 1950 : Le Test de Turing. Alan Turing a posé une question essentielle. « Les machines peuvent-elles penser ? » Son test a défini l’intelligence machine.
- 1952 : Le Jeu de Dames d’Arthur Samuel. Un scientifique d’IBM, Arthur Samuel, a conçu un programme. Il jouait aux dames et apprenait seul. Il a inventé le terme « machine learning ». Certains disent en 1959. Je le considère comme le “Père du Machine Learning”.
Percées et Revers Initiaux (Années 1950-1970)
L’enthousiasme initial a laissé place à une période de doutes.
- 1957 : Le Perceptron. Frank Rosenblatt a développé le Perceptron. C’était le premier réseau neuronal pour la reconnaissance d’images.
- 1967 : La Reconnaissance de Formes. L’algorithme du plus proche voisin est apparu. Il a marqué le début de la reconnaissance de formes basique. Pensez aux cartes routières.
- 1969 : L’« Hiver de l’IA ». Marvin Minsky et Seymour Papert ont mis en lumière des limites. Les réseaux neuronaux ne pouvaient pas résoudre certains problèmes. Les problèmes non-linéaires, comme le XOR. Le financement et la recherche ont chuté. C’était un coup dur.
Le Renouveau et la Spécialisation (Années 1980-1990)
Le domaine s’est réorganisé. On a délaissé l’IA générale. On a visé des problèmes pratiques et solubles.
- Années 1980 : La Rétropropagation. L’algorithme de rétropropagation a été réinventé. Les réseaux neuronaux multicouches pouvaient apprendre de leurs erreurs. L’intérêt a repris vie.
- Années 1990 : L’Apprentissage Statistique. Le domaine a prospéré. Il a intégré les statistiques et les probabilités. Le développement des Machines à Vecteurs de Support et des Forêts Aléatoires (1995) a été crucial.
- 1997 : Deep Blue. Deep Blue d’IBM a battu Garry Kasparov. C’était le champion du monde d’échecs. Cela a montré la puissance du ML computationnel. Il surpassait l’habileté humaine.
L’Ère Moderne : Deep Learning et Big Data (Années 2000-Aujourd’hui)
L’alliance de vastes ensembles de données (Big Data) et de la puissance de calcul (GPU) a mené aux avancées actuelles.
- 2006 : Le Deep Learning. Geoffrey Hinton a renommé la recherche sur les réseaux neuronaux. Il l’a appelée “Deep Learning”. Cela a permis d’entraîner des réseaux beaucoup plus profonds.
- 2012 : ImageNet. L’algorithme AlexNet a réalisé une percée. C’était lors de la compétition ImageNet. Il a prouvé la supériorité des réseaux neuronaux profonds. Ils étaient meilleurs pour la reconnaissance visuelle.
- Années 2020 : L’IA Générative. Les Grands Modèles de Langage (LLM) sont apparus. ChatGPT d’OpenAI (2022) ou AlphaFold de Google (pour la prédiction de structures protéiques). Ils ont propulsé le machine learning au cœur des conversations mondiales.
Voici quelques figures marquantes :
| Figure Notable | Contribution |
|---|---|
| Alan Turing | Fondation théorique de l’intelligence machine (Test de Turing) |
| Arthur Samuel | A inventé “Machine Learning” ; programme de jeu de dames auto-apprenant |
| Frank Rosenblatt | A inventé le Perceptron (premier réseau neuronal) |
| Geoffrey Hinton | A relancé le domaine avec les techniques de “Deep Learning” |
| Yann LeCun | Pionnier des Réseaux Neuronaux Convolutifs (CNN) pour la reconnaissance d’images |
Pour en savoir plus sur cette histoire fascinante, je vous invite à consulter la page Wikipedia sur le Machine Learning.
Mon Point de Vue sur les Relations du Machine Learning avec d’Autres Domaines
Le machine learning est par nature interdisciplinaire. Il agit comme un pont. Il relie les sciences mathématiques fondamentales à divers domaines appliqués. Ses relations vont des sous-ensembles théoriques aux partenariats complexes.
Relations Fondamentales Clés
Le ML se situe à l’intersection de plusieurs disciplines techniques primaires.
- Intelligence Artificielle (IA) : Le ML est un sous-ensemble de l’IA. L’IA est l’objectif général. Créer des machines qui imitent l’intelligence humaine. Le raisonnement, l’action. Le ML fournit les méthodes spécifiques. Celles qui permettent à ces machines d’apprendre des données. Plutôt que de suivre des règles statiques.
- Statistiques : Ces deux domaines sont profondément liés. Les statistiques se concentrent sur l’inférence. Comprendre comment les données sont créées. Le ML se concentre sur la prédiction. Minimiser les erreurs. Sans nécessairement comprendre le mécanisme sous-jacent. De nombreux algorithmes ML sont des applications computationnelles. Des méthodes statistiques, en somme.
- Science des Données : Le ML est un outil essentiel. Il s’inscrit dans le cycle de vie de la science des données. La science des données gère le processus de bout en bout. Collecte, nettoyage, visualisation des données. Pour trouver des informations. Le ML est utilisé spécifiquement. Pour construire des modèles prédictifs. À partir de ces données préparées.
Connexions Interdisciplinaires
Le ML s’intègre de plus en plus. Il collabore avec d’autres domaines spécialisés. Pour résoudre des problèmes concrets.
- Robotique : Cette collaboration crée des systèmes autonomes. Le ML fournit le « cerveau ». Pour des tâches comme la vision, le contrôle du mouvement, la préhension. La robotique fournit le matériel physique. Pour interagir avec l’environnement.
- Sciences Cognitives & Psychologie : Le ML imite souvent les processus d’apprentissage biologique. Les chercheurs utilisent des modèles ML. Pour tester des théories sur la cognition humaine. Les idées de la neuroscience et de la psychologie. Elles inspirent de nouvelles architectures de réseaux neuronaux.
- Linguistique : Par le Traitement du Langage Naturel (TLN), le ML permet aux machines. De comprendre et générer le langage humain. Il s’appuie sur la théorie linguistique. Pour gérer les nuances. Le contexte, le sentiment, la traduction.
- Ingénierie : La recherche opérationnelle et la théorie du contrôle. Elles fournissent des cadres d’optimisation mathématique. De nombreux algorithmes ML les utilisent. Pour trouver la « meilleure » solution pendant l’entraînement.
Résumé des Distinctions Clés
| Relation | Distinction Clé |
|---|---|
| vs. IA | L’IA est le “but” (action intelligente) ; le ML est le “moyen” (apprendre des données). |
| vs. Science des Données | La science des données produit des insights pour les humains ; le ML produit des prédictions pour les systèmes. |
| vs. Statistiques | Les statistiques privilégient la compréhension du “pourquoi” ; le ML privilégie la prédiction précise du “quoi”. |
Le Machine Learning au Quotidien : Mes Observations sur les Applications
Les applications du machine learning sont partout. Elles sont intégrées dans presque toutes les industries. Elles transforment des montagnes de données. Elles en tirent des informations exploitables. Elles automatisent les décisions.
Applications Quotidiennes Courantes
De nombreux outils que nous utilisons. Ils s’appuient sur le ML en coulisses. Pour fonctionner en douceur.
- Assistants Virtuels : Alexa d’Amazon et Siri d’Apple utilisent le Traitement du Langage Naturel. Pour reconnaître la parole. Pour répondre aux commandes.
- Moteurs de Recommandation : Netflix, Amazon, Spotify. Ces plateformes analysent votre historique. Pour suggérer des films, des produits, de la musique. Je trouve cela incroyablement utile.
- Filtrage d’E-mails : Les modèles ML classifient automatiquement les e-mails. Ils les placent dans les dossiers principaux, sociaux ou de spam.
- Navigation : Google Maps utilise le ML. Pour prédire les conditions de trafic. Pour calculer les itinéraires les plus rapides.
Cas d’Utilisation Spécifiques à l’Industrie
Les secteurs professionnels utilisent le ML. Pour résoudre des problèmes complexes. Pour augmenter l’efficacité.
- Santé :
- Diagnostic Médical : Les algorithmes ML analysent les scanners médicaux. Pour identifier des maladies. Le cancer ou la pneumonie. Avec une grande précision.
- Découverte de Médicaments : Les modèles prédisent les interactions moléculaires. Pour accélérer le développement de nouveaux médicaments.
- Finance :
- Détection de Fraude : Les banques utilisent le ML. Pour surveiller les transactions en temps réel. Elles signalent instantanément les schémas suspects.
- Trading Algorithmique : Les institutions financières utilisent des modèles prédictifs. Pour prévoir les tendances du marché. Pour exécuter des transactions à haute vitesse.
- Fabrication :
- Maintenance Prédictive : Des capteurs sur les machines. Ils alimentent les modèles ML en données. Ces modèles prédisent les pannes avant qu’elles ne surviennent.
- Contrôle Qualité : Les systèmes de vision par ordinateur inspectent les produits. Sur les chaînes d’assemblage. Ils cherchent les moindres défauts.
- Commerce de Détail :
- Prévision de la Demande : Des détaillants comme H&M utilisent le ML. Pour prévoir les besoins en stocks. Cela réduit le gaspillage et les ruptures de stock.
- Tarification Dynamique : Les algorithmes ajustent les prix en temps réel. En fonction de la demande et de l’activité des concurrents.
Frontières Émergentes
Le ML continue d’ouvrir de nouvelles voies.
- Véhicules Autonomes : Les voitures sans conducteur. Elles traitent d’énormes quantités de données de capteurs. Pour naviguer en toute sécurité. Sans intervention humaine.
- IA Générative : Des outils comme ChatGPT et DALL-E. Ils créent des textes, des images, des vidéos originaux. À partir de simples invites.
- Cybersécurité : Les modèles ML détectent les logiciels malveillants et les tentatives de phishing. Ils identifient les anomalies dans le trafic réseau.
Les Obstacles du Machine Learning : Mes Réflexions sur les Limites
Le machine learning est un transformateur. Mais il fait face à des limitations. Des limites techniques, éthiques et pratiques. Elles peuvent entraver son efficacité. Dans des applications réelles.
Limitations Techniques et Liées aux Données
Nos modèles ne valent que par leurs données. C’est une vérité fondamentale.
- Dépendance aux Données :
- Qualité : Des informations incomplètes. Bruyantes ou obsolètes. Elles mènent à des prédictions inexactes.
- Quantité : Des architectures complexes. Les réseaux neuronaux. Ils exigent des quantités massives de données étiquetées. Pour fonctionner de manière fiable.
- Le Problème de la “Boîte Noire” : Les modèles avancés. Surtout le deep learning. Ils manquent souvent d’interprétabilité. Il est difficile pour les humains. De comprendre la logique derrière une décision spécifique. C’est un obstacle majeur. Dans des domaines à enjeux élevés. Comme la santé et la finance.
- Problèmes de Généralisation :
- Surapprentissage (Overfitting) : Le modèle apprend trop bien le bruit. Dans les données d’entraînement. Il échoue sur de nouvelles données. Des données inédites.
- Sous-apprentissage (Underfitting) : Le modèle est trop simple. Il ne capture pas les motifs sous-jacents. Cela entraîne des performances médiocres.
- Nature Stochastique : Contrairement aux systèmes déterministes. Les modèles ML donnent des résultats probabilistes. Ils peuvent violer les lois physiques. Prédire une pression d’air négative. Dans les modèles météorologiques, par exemple. Ils ne comprennent pas la science sous-jacente.
Contraintes Éthiques et Sociétales
L’impact du ML dépasse le code. Il touche nos valeurs.
- Biais Algorithmique : Si les données d’entraînement. Elles reflètent des préjugés humains. Racisme, sexisme, etc. Le modèle automatisera et amplifiera ces biais. C’est un défi crucial.
- Manque de Bon Sens : Les machines manquent d’intuition humaine. De compréhension contextuelle. Elles luttent avec l’ambiguïté. Les métaphores. Les “cas limites”. Des situations inhabituelles qu’elles n’ont pas vues à l’entraînement.
- Risques de Confidentialité : L’entraînement des modèles exige de vastes quantités de données. Elles incluent souvent des informations sensibles. Personnelles ou propriétaires. Elles sont susceptibles de fuites. Ou d’une mauvaise utilisation. Ces risques sont bien documentés, comme on peut le lire dans cet article sur les questions éthiques de l’IA et du ML.
- Causalité vs. Corrélation : Le ML excelle à trouver des corrélations. Deux choses se produisant ensemble. Mais il peine à déterminer la causalité. Une chose en provoquant une autre.
Obstacles en Matière de Ressources et d’Opérations
Le déploiement du ML n’est pas sans effort.
- Coûts Élevés : Le développement et la maintenance des modèles ML. Ils exigent du matériel spécialisé coûteux (GPU). Une consommation d’énergie importante. Des experts hautement qualifiés.
- Impact Environnemental : La puissance de calcul massive. Nécessaire pour entraîner de grands modèles. Elle contribue à une empreinte carbone significative. C’est une préoccupation croissante.
- Vulnérabilité aux Attaques : Les “attaques adversariales”. De minuscules changements, imperceptibles par l’homme. Dans les données d’entrée. Elles peuvent facilement tromper les modèles. Les faire commettre des erreurs catastrophiques.
L’IA Explicable (XAI) : Mon Engagement pour la Transparence
L’IA explicable (XAI) est un ensemble de principes. Ce sont aussi des méthodes techniques. Elles rendent les modèles de machine learning « boîtes noires » transparents. Leur logique interne est trop complexe. Pour être comprise par les humains. La XAI agit comme un « traducteur ». Entre les mathématiques de la machine et le raisonnement humain. C’est essentiel pour les décisions à enjeux élevés. En santé ou en finance.
Techniques et Méthodes Fondamentales
Les techniques XAI se classent généralement. Selon le moment de leur application. Et ce qu’elles expliquent.
- Par Conception (Intrinsèquement Interprétables) : Ce sont des modèles « boîtes blanches ». Ils sont assez simples pour être compris. Sans outils supplémentaires.
- Arbres de Décision : Ils montrent un chemin logique clair. Un chemin « si-alors ».
- Régression Linéaire/Logistique : Ils utilisent des coefficients pondérés. Pour montrer l’influence exacte de chaque caractéristique. L’âge ou le revenu, par exemple.
- Explications Post-Hoc : Utilisées pour expliquer des modèles complexes. Après leur entraînement.
- SHAP (Shapley Additive Explanations) : Basé sur la théorie des jeux. Il attribue une « valeur d’importance ». À chaque caractéristique d’entrée. Pour une prédiction spécifique.
- LIME (Local Interpretable Model-Agnostic Explanations) : Explique une seule prédiction. Il crée un modèle temporaire, simplifié. Autour de cette prédiction.
- Explications Contrefactuelles : Explique une décision. Il montre le changement minimal nécessaire. Pour obtenir un résultat différent. « Si votre revenu était supérieur de 5 000 $, le prêt aurait été approuvé ».
- Visualisations :
- Saliency/Heatmaps (Grad-CAM) : Met en évidence des régions spécifiques dans une image. Un scanner médical. Celles qui ont le plus influencé la décision du modèle.
- Cartes d’Attention : En TLN ou avec les Transformers. Elles montrent les mots spécifiques. Sur lesquels le modèle s’est concentré. Lors de la génération d’une réponse.
Principaux Outils et Bibliothèques XAI
Les data scientists utilisent des bibliothèques open source spécialisées. Pour appliquer ces méthodes.
- SHAP : Le standard d’or pour l’importance des caractéristiques. Fonctionne avec presque tous les modèles.
- LIME : Populaire pour les explications locales, spécifiques à l’instance.
- InterpretML : Une bibliothèque soutenue par Microsoft. Elle unifie de nombreuses techniques XAI. Sous un même parapluie.
- Alibi : Connu pour sa documentation de haute qualité. Et son support pour les contrefactuels et les ancres.
- AIX360 : Le kit d’outils complet d’IBM. Spécialement conçu pour l’entreprise. Et la conformité réglementaire.
- Captum : Une bibliothèque spécialisée pour les utilisateurs de PyTorch. Pour interpréter les réseaux neuronaux.
Cas d’Utilisation Clés
| Industrie | Application XAI | Bénéfice |
|---|---|---|
| Santé | Expliquer pourquoi une radiographie a été signalée comme “suspecte”. | Construit la confiance des cliniciens ; détecte les anomalies subtiles. |
| Finance | Justifier les refus de prêt ou les notations de crédit. | Respecte les exigences légales (ex. GDPR) ; prévient les biais. |
| Robotique | Expliquer les manœuvres autonomes. | Essentiel pour la sécurité et l’acceptation publique des voitures autonomes. |
| Droit | Suivi de la logique dans les prédictions de cas ou l’examen de documents. | Assure la responsabilité et l’équité dans les décisions sensibles. |
Le Matériel du Machine Learning : Mon Guide des Accélérateurs IA
Le matériel du machine learning a beaucoup évolué. Des processeurs informatiques standard. Aux « accélérateurs IA » hautement spécialisés. Conçus pour des calculs parallèles massifs. Le développement ML moderne. Il repose généralement sur une combinaison. Des GPU haute performance. Et des ASICs construits sur mesure.
Unités de Traitement Principales
- GPU (Graphics Processing Units) : Le choix le plus courant pour le deep learning. Leurs milliers de cœurs excellent. Dans la « multiplication matricielle ». C’est le calcul de base des réseaux neuronaux.
- NVIDIA est le leader de l’industrie. Grâce à son écosystème logiciel CUDA.
- Choix pour les Consommateurs : GeForce RTX 4090 (24 Go VRAM). Pour les chercheurs et les startups.
- Choix pour les Entreprises : NVIDIA A100 et H100/B200. Pour l’entraînement à grande échelle. Dans les centres de données.
- TPU (Tensor Processing Units) : Puces personnalisées développées par Google. Spécifiquement pour TensorFlow et les charges de travail JAX. Elles offrent une meilleure efficacité énergétique et un débit plus élevé. Pour l’entraînement à grande échelle. Mais elles sont principalement exclusives à Google Cloud. Je trouve leur spécialisation impressionnante.Pour une comparaison détaillée, lisez l’article sur les différences entre TPU et GPU.
- CPU (Central Processing Units) : Utilisés pour le prétraitement des données. Les modèles ML simples. Et l’inférence en temps réel. Sur des modèles plus petits. Ils sont moins efficaces pour l’entraînement du deep learning. Comparés aux GPU.
Matériel Spécialisé et Émergent
- LPU (Language Processing Units) : Développées par des startups comme Groq. Ces puces sont optimisées. Spécifiquement pour l’inférence à haute vitesse. Requise par les Grands Modèles de Langage (LLM).
- NPU (Neural Processing Units) : Intégrées dans les smartphones modernes. Comme les séries A d’Apple. Ou les Snapdragon de Qualcomm. Pour gérer les tâches d’IA sur l’appareil. La reconnaissance faciale et le traitement photo. Tout en économisant la batterie.
- FPGA (Field-Programmable Gate Arrays) : Matériel reconfigurable. Souvent utilisé lorsque une latence ultra-faible. Et le déterminisme sont requis. Comme dans les télécommunications ou l’imagerie médicale.
Exigences du Système pour le ML
| Composant | Recommandation |
|---|---|
| VRAM (Mémoire GPU) | 8-12 Go pour les débutants ; 24 Go+ pour le fine-tuning LLM ; 48-80 Go pour l’entreprise. |
| RAM Système | Au moins le double de la VRAM de votre GPU (ex. 32 Go RAM pour un GPU de 16 Go). |
| Stockage | Des SSD NVMe haute vitesse (1 To+) sont essentiels pour éviter les goulots d’étranglement de chargement des données. |
Ma Sélection de Logiciels Libres pour le Machine Learning
L’écosystème du machine learning repose majoritairement sur le logiciel libre et open source (FOSS). Il permet aux développeurs de construire, entraîner et déployer des modèles. Sans coûts de licence propriétaires. Ces outils vont des bibliothèques fondamentales. Aux plateformes complètes. Pour gérer tout le cycle de vie du machine learning.
Frameworks et Bibliothèques Fondamentales
Ce sont les outils essentiels. Pour construire et entraîner des modèles de machine learning.
- Scikit-learn : Le standard pour le machine learning « classique ». Classification, régression, clustering. Il est très apprécié. Pour son API conviviale pour les débutants. Et sa documentation robuste.
- PyTorch : Un framework de deep learning flexible. Préféré par les chercheurs. Pour ses graphes de calcul dynamiques. Ils facilitent le débogage.
- TensorFlow : Une plateforme de deep learning mature. Développée par Google. Connue pour son évolutivité prête pour la production. Et son écosystème étendu (comme TFX et TensorFlow Lite).
- Keras : Une API de haut niveau. Elle fonctionne au-dessus de TensorFlow, PyTorch ou JAX. Conçue pour le prototypage rapide de réseaux neuronaux.
- XGBoost / LightGBM : Des bibliothèques haute performance. Spécifiquement pour les arbres de décision. À gradient boosté. Largement utilisées dans les compétitions. Et les tâches de données structurées.
Traitement et Visualisation des Données
- Pandas : La bibliothèque première. Pour la manipulation et l’analyse des données. En utilisant des « DataFrames ». Ils fonctionnent comme des feuilles de calcul avancées.
- NumPy : Le package fondamental. Pour le calcul scientifique avec Python. Il fournit les structures de tableaux multidimensionnels (tenseurs). Sur lesquelles la plupart des bibliothèques ML s’appuient.
- OpenCV : Le standard de l’industrie. Pour la vision par ordinateur en temps réel. Et les tâches de traitement d’images.
- Matplotlib / Seaborn : Des bibliothèques essentielles. Pour créer des visualisations de données statiques, interactives et animées.
MLOps et Gestion du Cycle de Vie
Ces outils aident à la transition des modèles. Des expériences locales. Vers des environnements de production stables.
- MLflow : Une plateforme open source. Pour suivre les expériences. Empaqueter le code en exécutions reproductibles. Et gérer un registre de modèles central.
- Kubeflow : Une plateforme cloud-native. Conçue pour exécuter des workflows de machine learning. Sur Kubernetes. Les rendant portables et évolutifs.
- DVC (Data Version Control) : Un outil open source. Il fonctionne avec Git. Pour versionner de grands ensembles de données. Et des modèles de machine learning.
- Apache Airflow : Une plateforme pour l’auteurisation, la planification et la surveillance. Programmatiques. Des pipelines complexes de données et de ML.
Référentiels de Données Ouverts
Les logiciels libres sont utiles. Mais ils ont besoin de données. Ces plateformes offrent un accès gratuit. À des millions d’ensembles de données open source.
- Kaggle Datasets : Un référentiel massif. Alimenté par la communauté. Avec des ensembles de données diversifiés. Pour chaque niche.
- UCI Machine Learning Repository : L’une des sources les plus anciennes et les plus fiables. Pour les données de machine learning académiques.
- Hugging Face Hub : Le hub central. Pour les modèles de Traitement du Langage Naturel (TLN) open source. Et les ensembles de données.
Les Conférences ML : Mon Calendrier des Innovations Futures
Les conférences sur le machine learning sont capitales. Elles sont le lieu de diffusion des recherches de pointe. Elles permettent de réseauter avec les leaders de l’industrie. De découvrir de nouveaux outils. Le domaine est dominé par quelques conférences universitaires « de premier plan ». Des événements industriels à grande échelle les complètent. Ceux-ci se concentrent sur le déploiement et l’infrastructure.
Conférences de Recherche de Premier Plan (2026)
Ces lieux sont très sélectifs. Les recherches sont évaluées par les pairs. Les grandes avancées y sont généralement présentées. Nouvelles architectures neuronales. Méthodes d’optimisation. C’est l’avant-garde.
| Conférence | Dates 2026 | Lieu | Focus Principal |
|---|---|---|---|
| AAAI | 20-27 janv. | Singapour | IA générale, éthique et systèmes de raisonnement |
| ICLR | 23-27 avr. | Rio de Janeiro, Brésil | Deep learning et apprentissage de représentations |
| CVPR | 6-12 juin | Denver, CO, USA | Vision par ordinateur et reconnaissance de formes |
| ICML | 6-12 juil. | Séoul, Corée du Sud | Théorie du ML, apprentissage par renforcement et robotique |
| IJCAI-ECAI | 15-21 août | Brême, Allemagne | IA générale et recherche fondamentale |
| KDD | 9-13 août | Jeju, Corée du Sud | Exploration de données et découverte de connaissances |
| NeurIPS | 6-12 déc. | Sydney, Australie | Traitement de l’information neuronale et deep learning |
Pour moi, NeurIPS est toujours un événement majeur. Il fixe souvent le cap. Vous pouvez en savoir plus sur leur site : NeurIPS.
Événements Industriels et d’IA Appliquée
Ces événements priorisent le « comment faire ». Du machine learning. Ils se concentrent sur le MLOps. L’infrastructure à grande échelle. Et les applications commerciales.
- NVIDIA GTC (16-19 mars 2026 | San Jose, CA) : L’événement majeur. Pour le calcul accéléré par GPU. Et l’infrastructure matérielle d’IA.
- MLOps World (Dates variées) : Spécifiquement axé sur les défis. Du déploiement et de la gestion des modèles. En production.
- Ai4 (4-6 août 2026 | Las Vegas, NV) : L’un des plus grands événements industriels d’IA en Amérique du Nord. Il couvre des secteurs comme la finance, la santé et le commerce de détail.
- MLsys (17-22 mai 2026 | Bellevue, WA) : Une conférence spécialisée. Elle se concentre sur l’intersection. Des algorithmes ML et de la conception de systèmes.
- Machine Learning Week (4-7 mai 2026 | San Francisco, CA) : Se concentre sur l’« IA Hybride ». Et le passage des modèles prédictifs. Du développement au déploiement.
Lieux de Domaines Spécialisés
Si vous travaillez dans un sous-domaine spécifique. Ces conférences sont souvent plus pertinentes. Que les lieux ML généraux.
- TLN : ACL (2-7 juillet 2026 | San Diego, CA) est le principal lieu. Pour le traitement du langage naturel.
- Robotique : CoRL se concentre exclusivement. Sur l’intersection de l’apprentissage robotique. Et du contrôle.
- Médical : MICCAI (4-8 oct. 2026 | Abu Dhabi, EAU) est l’événement leader. Pour l’informatique d’imagerie médicale. Et l’intervention assistée par ordinateur.