Aujourd’hui, je vous parle de Gemma 4. C’est la dernière merveille de Google. Le 2 avril 2026, elle a fait son entrée. Une nouvelle ère commence pour les modèles d’IA open-weight. Gemma 4 se base sur la recherche de la famille Gemini 3. C’est un modèle sous licence Apache 2.0. Cela signifie une liberté totale. Vous l’utilisez pour vos projets personnels. Vos applications commerciales sont aussi les bienvenues. C’est une porte ouverte sur l’innovation. J’adore cette approche. Cela rend l’IA de pointe accessible à tous. Imaginez les possibilités!
Ses points forts sont nombreux. Elle excelle en raisonnement avancé. Sa multimodalité est étendue. Les workflows agentiques sont renforcés. Les fenêtres de contexte sont immenses. Le support multilingue est impressionnant. Gemma 4 n’est pas qu’un simple modèle. C’est une boîte à outils complète. Elle va transformer vos développements IA. C’est une révolution discrète.
Variantes Clés de Gemma 4

La famille Gemma 4 se décline en quatre tailles. Chacune a un rôle précis. Elles s’adaptent à divers besoins. Des téléphones aux stations de travail. Google a pensé à tout.
- E2B (Effective 2B) & E4B (Effective 4B) : Ce sont nos modèles “Edge”. Ils sont parfaits pour les appareils mobiles. Pensez aux navigateurs comme Chrome. L’utilisation embarquée est leur terrain de jeu. Ils sont légers, mais puissants. C’est de l’IA dans votre poche.
- 26B A4B (MoE) : Voici un modèle “Mixture-of-Experts”. Il intègre 26 milliards de paramètres au total. Seulement 4 milliards sont actifs à l’usage. Cela garantit une haute qualité. Les coûts de calcul restent faibles. C’est un équilibre intelligent.
- 31B Dense : C’est le champion de la famille. Ce modèle offre des performances de serveur. Vous pouvez l’exécuter localement. Il demande une machine puissante. Il pousse les limites. Je suis toujours émerveillé par sa capacité.
Capacités Fondamentales : Qu’est-ce que Gemma 4 apporte?
Gemma 4 ne se contente pas d’être rapide. Elle intègre des améliorations architecturales profondes. Ses fonctionnalités sont vraiment fascinantes.
- Raisonnement Avancé : Tous les modèles ont un mode “Réflexion” intégré. Ils planifient des processus complexes. Une analyse logique approfondie précède la réponse. C’est comme avoir un petit génie qui réfléchit pour vous.
- Multimodalité Étendue : Texte, images, vidéo. Tout est pris en charge. Les versions E2B et E4B ajoutent le traitement audio. Reconnaissance vocale, traduction, elles gèrent tout. C’est la polyvalence incarnée.
- Workflows Agentiques : L’intégration d’agents est améliorée. Appels de fonctions natifs sont inclus. Des sorties JSON structurées sont générées. Elles suivent les instructions à la lettre. Vos agents deviennent plus intelligents.
- Grandes Fenêtres de Contexte : Les petits modèles gèrent jusqu’à 128K tokens. Les versions 26B et 31B supportent jusqu’à 256K tokens. C’est une mémoire de conversation gigantesque.
- Support Multilingue : Ces modèles ont été entraînés sur plus de 140 langues. Ils prennent en charge 35+ langues prêtes à l’emploi. La communication devient globale.
Performances et Disponibilité
Les premiers tests sont impressionnants. Le modèle 31B Dense s’est classé 3e sur le classement textuel d’Arena AI. Il a surpassé des modèles bien plus grands. C’est un exploit. Les développeurs accèdent à Gemma 4. Cela se fait via Google AI Studio. D’autres plateformes sont aussi disponibles. Vous la trouvez sur Hugging Face, Kaggle et Ollama. C’est une disponibilité étendue. Allez-y, explorez!
Voici des liens pour les curieux :
- Collection Gemma 4 sur Hugging Face
- Modèles Gemma 4 sur Kaggle
- Bibliothèque Gemma 4 sur Ollama
- Support Android Studio pour Gemma 4 local
Statistiques Clés de Gemma 4
Les statistiques de Gemma 4 révèlent une famille robuste. Quatre modèles multimodaux sont disponibles. Leurs architectures sont variées. Les fenêtres de contexte et les niveaux de performance diffèrent. Tout cela depuis leur lancement, le 2 avril 2026.
Spécifications Détaillées des Modèles
J’ai réuni les informations cruciales dans ce tableau. Il vous aidera à y voir plus clair.
| Propriété | E2B (Edge) | E4B (Edge) | 26B A4B (MoE) | 31B (Dense) |
|---|---|---|---|---|
| Paramètres Totaux | 5.1B (2.3B actifs) | 8B (4.5B actifs) | 25.2B | 30.7B |
| Paramètres Actifs | 2.3B | 4.5B | 3.8B | 30.7B |
| Fenêtre de Contexte | 128K tokens | 128K tokens | 256K tokens | 256K tokens |
| Fenêtre Coulissante | 512 tokens | 512 tokens | 1024 tokens | 1024 tokens |
| Couches | 35 | 42 | 30 | 60 |
| Modalités | Texte, Image, Audio | Texte, Image, Audio | Texte, Image | Texte, Image |
Benchmarks de Performance Clés
Comparateur interactif des benchmarks Gemma 4 — filtrez par catégorie et modèles pour comparer les scores
Les modèles montrent des gains significatifs. Ils surpassent les versions précédentes. Cela est particulièrement vrai en raisonnement et codage.
- AIME 2026 (Math) : Le 31B Dense obtient 89.2%. Le 26B MoE suit de près avec 88.3%. Le calcul est son ami.
- LiveCodeBench v6 : Le modèle 31B Dense atteint 80.0%. L’ancien Gemma 3 27B n’atteignait que 29.1%. C’est une énorme avancée.
- GPQA Diamond : Gemma 4 31B score 84.3%. Il surclasse de nombreux modèles plus grands. Le raisonnement scientifique est son domaine.
- Codeforces ELO : Le 31B Dense atteint un ELO de 2,150. C’est un bond colossal. Gemma 3 27B était à 110.
- Arena AI (Texte) : Le 31B Dense est classé 3e avec un ELO de 1452. Le 26B MoE est 6e avec 1441 ELO. Ils sont parmi les meilleurs.
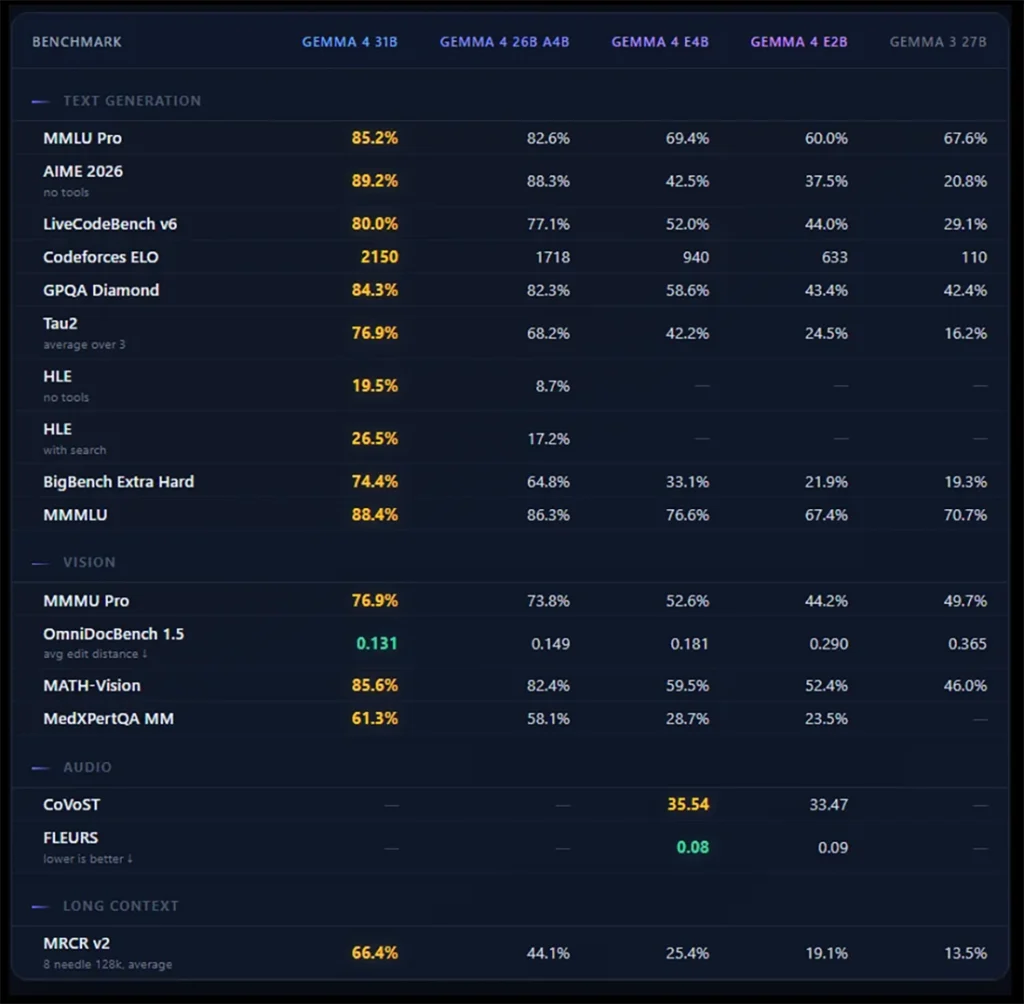
Raisonnement Spécialisé et Efficacité
Le mode “Réflexion” de Gemma 4 change la donne. Il pousse les modèles vers de nouveaux sommets. Les tâches scientifiques et logiques sont à sa portée.
- GPQA Diamond : Le 31B Dense atteint 85.7%. C’est le deuxième meilleur résultat pour un modèle open-weight. Il a moins de 40 milliards de paramètres. Impressionnant, non?
- Efficacité : Le modèle 31B obtient ces scores. Il utilise environ 1.2 million de tokens de sortie. Des concurrents comme Qwen 3.5 27B en demandent 1.5 million. Il fait plus avec moins.
- Préférence Humaine : Sur le leaderboard Arena AI, le 31B Dense a un ELO de 1452. Il est 3e mondial. La variante 26B MoE suit de près. Elle utilise seulement 3.8B paramètres actifs. Elle est 6e avec 1441 ELO.
Benchmarks Multimodaux Avancés
Les modèles Gemma 4 traitent nativement texte, images et vidéo. Les versions Edge ajoutent le support audio. C’est une polyvalence totale.
- MATH-Vision : Le modèle 31B Dense atteint 85.6%. Le petit E2B gère 52.4%. Les deux surpassent l’ancien Gemma 3 27B (46.0%).
- Performance Audio (Edge uniquement) : Le E4B obtient 35.54 sur CoVoST et 0.08 (moins est mieux) sur FLEURS. Cela permet une reconnaissance vocale fiable. La traduction embarquée est aussi possible.
- Analyse de Documents : Sur OmniDocBench 1.5, le modèle 31B a un edit distance moyen de 0.131. C’est bien mieux que les 0.365 de Gemma 3. La précision est notable.
A la une — Claude Mythos : La Légende de l’IA Surpuissante, ses Dangers et le Project Glasswing
Exigences Matérielles et VRAM
Les besoins en mémoire sont cruciaux. Ils dépendent de la quantification et du modèle spécifique. Gemma 4 est exigeante. Mais elle sait aussi être flexible.
Je vous préviens: si vous voulez du BF16 sur le 31B Dense, préparez votre portefeuille. Cela demande du gros matos. Mais pour la plupart d’entre nous, la quantification sauve la mise.
Estimations des Besoins en VRAM par Précision
Ces estimations couvrent la mémoire de base. C’est ce qu’il faut pour charger les poids du modèle. Une fenêtre de contexte plus grande augmentera aussi la VRAM nécessaire. Pensez au cache KV. Cela ajoute à la consommation.
| Modèle | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) |
|---|---|---|---|
| 31B (Dense) | 58.3 GB | 30.4 GB | 17.4 GB |
| 26B A4B (MoE) | 48.0 GB | 25.0 GB | 15.6 GB |
| E4B (Edge) | 15.0 GB | 7.5 GB | 5.0 GB |
| E2B (Edge) | 9.6 GB | 4.6 GB | 3.2 GB |
Recommandations Matérielles
- GPUs grand public haut de gamme (RTX 3090/4090/5090) : Ces cartes ont 24 Go de VRAM. Elles peuvent faire tourner confortablement le 31B Dense et le 26B A4B en précision 4 bits (Q4). Vous aurez même de la place pour une fenêtre de contexte modérée.
- GPUs de milieu de gamme (RTX 3060/4070 12 Go+) : Idéales pour le modèle E4B. Ou des versions très compressées des modèles plus grands. L’E4B en 4 bits n’utilise qu’environ 5 Go. Cela laisse un espace suffisant pour les tâches à long contexte.
- Appareils mobiles et Edge : L’E2B est conçu pour les contraintes de RAM mobiles. Il tient dans moins de 4 Go une fois quantifié. Parfait pour les smartphones modernes ou un Raspberry Pi 5.
- Matériel d’entreprise (A100/H100 80 Go) : Requis pour l’inférence BF16 complète du modèle 31B Dense. Ou pour l’entraînement et le fine-tuning. Ceux qui utilisent de grandes tailles de batchs en auront besoin.
Notes sur la Performance d’Inférence
- L’avantage MoE : Le modèle 26B A4B a 26 milliards de paramètres. Mais il n’active que 3.8 milliards pendant l’inférence. Il atteint ainsi des vitesses de 145 tokens/sec. C’est sur une RTX 4090. Il rivalise avec des modèles 4B beaucoup plus petits. La qualité reste supérieure.
- Impact de la Fenêtre de Contexte : Exécuter le modèle 31B à son plein contexte de 256K peut consommer 180-220 Go de RAM système supplémentaires. Ou de VRAM multi-GPU. Cela se produit si le cache KV n’est pas optimisé. Ou quantifié. C’est un point à surveiller.
Plus d’infos sont disponibles ici: Documentation Google AI sur Gemma.
Gemma 4 représente un bond en avant. Les tâches de raisonnement et multimodales en profitent. Le modèle 31B Dense est 20% plus efficace. Il surpasse des concurrents comme Qwen 3.5 27B. Il atteint des performances presque identiques. Mais avec moins de tokens de sortie. C’est malin.
A découvrir — Le Projet Stargate AI : Chiffres, Faits, et Tout ce que Vous Devez Savoir
Déploiement et Exécution de Gemma 4
Déployer Gemma 4 n’est pas compliqué. Plusieurs méthodes s’offrent à vous. Je vous guide pas à pas.
Avec Ollama : La Simplicité au Quotidien
Ollama est votre meilleur ami. C’est le moyen le plus simple d’exécuter ces modèles. Sur un GPU grand public, comme une RTX 3060. Ou une 4080, une 4090. Ollama gère la quantification et la mémoire. C’est transparent.
1. Installation d’Ollama
Installez la dernière version d’Ollama. Cela assure la compatibilité avec Gemma 4.
Pour macOS/Linux : Tapez
curl -fsSL https://ollama.com | shPour Windows : Téléchargez l’installateur depuis ollama.com.
2. Vérification de Votre Matériel
Avant de télécharger un modèle, vérifiez votre VRAM.
- 8 Go – 12 Go de VRAM : Optez pour
gemma4:2bou
gemma4:4b.
- 16 Go – 24 Go de VRAM : Vous pouvez exécuter
gemma4:26b(MoE) ou
gemma4:31bavec une quantification 4 bits.
- Mac Studio/64 Go+ RAM : Le modèle 31b tourne avec une précision plus élevée (8 bits).
3. Téléchargez et Exécutez le Modèle
Ouvrez votre terminal (ou l’invite de commande). Lancez la commande pour la version désirée. Ollama téléchargera les poids. Un chat interactif démarrera.
Pour le modèle Dense haute performance (recommandé pour GPU 24 Go) :
ollama run gemma4:31bPour le modèle Mixture-of-Experts (MoE) rapide :
ollama run gemma4:26bPour les performances “Edge” (mobile/laptop) :
ollama run gemma4:4b4. Utilisation du Mode “Réflexion”
Les modèles Gemma 4 intègrent une chaîne de raisonnement. Pour activer le mode “Réflexion” dans Ollama, demandez simplement au modèle de “réfléchir étape par étape”. Ou utilisez un prompt système.
Commande :
/set system "Vous êtes un assistant utile. Réfléchissez profondément avant de répondre."Le modèle affichera son processus de raisonnement. Ensuite, il fournira la réponse finale. C’est comme une petite fenêtre sur son âme numérique. Fascinant!
5. Gestion du Modèle
Une fois le chat lancé, utilisez ces raccourcis :
/bye: Quitter le chat.
/list: Voir les versions de Gemma 4 téléchargées.
/rm gemma4:31b: Supprimer le modèle pour libérer de l’espace disque.
Astuce de Pro : Accélérer l’Inférence
Si le modèle semble lent, assurez-vous qu’Ollama utilise votre GPU. Pas votre CPU. Vérifiez avec
nvidia-smi(Windows/Linux). Ou le Moniteur d’Activité (Mac). Faites-le pendant que le modèle génère du texte.
Créer un Modelfile dans Ollama
Un Modelfile personnalise Gemma 4. Il intègre des paramètres spécifiques. Comme une fenêtre de contexte de 256K. Ou une personnalité “Réflexion”.
1. Création du Modelfile
Créez un fichier texte. Nommez-le
Modelfile(sans extension). Mettez-le dans n’importe quel dossier. Collez cette configuration :
# Choisissez votre modèle de base (31b, 26b, ou 4b)
FROM gemma4:31b
Définissez la fenêtre de contexte (Gemma 4 supporte jusqu'à 256,000)
Note : Des valeurs plus élevées nécessitent beaucoup plus de VRAM/RAM
PARAMETER num_ctx 32768
Définissez la température (plus bas = plus concentré, plus haut = plus créatif)
PARAMETER temperature 0.7
Définissez le System Prompt pour activer le mode "Réflexion"
SYSTEM """
Vous êtes Gemma 4, une IA très avancée.
Utilisez toujours votre mode de "Réflexion" interne pour planifier des tâches complexes.
Soyez concis, technique si nécessaire, et vérifiez toujours votre logique.
"""2. Construisez Votre Modèle Personnalisé
Ouvrez votre terminal. Allez dans le dossier du fichier. Exécutez cette commande pour “cuire” le modèle :
ollama create gemma4-pro -f Modelfile(Remplacez
gemma4-propar le nom de votre choix.)
3. Exécutez Votre Nouvelle Version
Lancez votre version personnalisée. Ne lancez plus la version par défaut.
ollama run gemma4-pro4. Ajustements Avancés des Paramètres
Vous avez une configuration haut de gamme? (24 Go+ de VRAM, par exemple). Ajoutez ces lignes à votre Modelfile. Elles pousseront les performances :
PARAMETER num_predict 4096: Augmente la longueur maximale de la réponse.
PARAMETER repeat_penalty 1.1: Empêche le modèle de se bloquer en boucle. Utile lors de longues chaînes de raisonnement.
PARAMETER num_gpu 99: Force Ollama à décharger autant de couches que possible sur votre GPU.
Note Importante sur le Contexte (num_ctx)
Gemma 4 supporte 256K tokens. Mais définir
num_ctx 256000va probablement faire planter un GPU grand public. Le cache KV grossit énormément. Commencez à
32768. Augmentez-le seulement si votre matériel gère la charge. Soyez prudent.
Pour le codage, vous voulez que Gemma 4 exploite ses scores LiveCodeBench élevés. Son mode “Réflexion” doit servir à l’architecture. Avant d’écrire une seule ligne. Pour l’écriture créative, concentrez-vous sur le flux narratif. Et les détails sensoriels.
1. Le “Software Architecte” (Codage et Débogage)
Ce prompt oblige le modèle à planifier la logique. Gérer les cas extrêmes. Utiliser une syntaxe moderne. Avant de sortir le bloc de code.
SYSTEM """
Vous êtes un Architecte Logiciel Senior.
Lorsqu'on vous demande de coder :
1. RÉFLÉCHISSEZ : Déconstruisez les exigences et planifiez les structures de données.
2. BRAINSTORMING : Identifiez les cas limites potentiels ou les risques de sécurité.
3. EXÉCUTEZ : Fournissez un code propre, modulaire et documenté.
4. REVUE : Expliquez brièvement pourquoi vous avez choisi des bibliothèques ou des modèles spécifiques.
Utilisez Markdown pour tous les blocs de code et priorisez la performance.
"""2. Le “Maître des Mots” (Écriture Créative)
Ce prompt pousse Gemma 4 à éviter les “AI-ismes”. Les répétitions de mots. Il se concentre sur “montrer, pas dire”.
SYSTEM """
Vous êtes un romancier et éditeur primé.
Votre style d'écriture est immersif. Vous favorisez les détails sensoriels. Les introspections nuancées des personnages.
RÉFLÉCHISSEZ : Cartographiez l'arc émotionnel de la scène avant d'écrire.
Évitez les clichés et les structures de phrases répétitives.
Si on vous demande de critiquer, soyez honnête mais constructif. Concentrez-vous sur le rythme et la voix.
"""Comment Mettre à Jour Votre Modèle
Ouvrez votre Modelfile.
Remplacez la section
SYSTEMpar l’un des prompts ci-dessus.
Exécutez à nouveau la commande
createpour écraser :
ollama create gemma4-pro -f ModelfileAstuce Rapide pour les Tests
Après avoir lancé
ollama run gemma4-pro, essayez de demander :
- Codage : “Écris un script Python pour gérer les requêtes API concurrentes avec un backoff de limite de réessais.”
- Créatif : “Décris un marché animé sur une planète avec deux soleils. Concentre-toi uniquement sur les odeurs et les sons.”
Avec vLLM : Pour un Débit Élevé
vLLM offre un service à haut débit. Il utilise une API compatible OpenAI. Il demande une gestion de mémoire plus attentive qu’Ollama.
1. Prérequis et Environnement
Gemma 4 nécessite Transformers v5.5.0 ou ultérieure. Assurez-vous que votre environnement est à jour.
pip install -U vllm transformers torch accelerate
# Installez timm pour le support vision/multimodal
pip install -U timm2. Lancement du Serveur vLLM
Utilisez la commande
vllm servepour démarrer le serveur API. Vous devez inclure des analyseurs spécifiques. C’est pour les capacités d’appel d’outils et de raisonnement de Gemma 4.
Pour le Modèle 31B Dense (Recommandé pour GPU 24 Go+) :
vllm serve google/gemma-4-31B-it \
--max-model-len 32768 \
--trust-remote-code \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--gpu-memory-utilization 0.95Pour le Modèle 26B A4B (MoE) (Haute Vitesse) :
vllm serve google/gemma-4-26B-A4B-it \
--max-model-len 262144 \
--kv-cache-dtype fp8 \
--trust-remote-code3. Optimisation de la VRAM pour une Utilisation Locale
Gemma 4 utilise une grande dimension de tête (256). Cela rend son cache KV beaucoup plus grand. C’est comparé aux modèles précédents.
- Réduire le Contexte : Utilisez
--max-model-lenpour plafonner la fenêtre de contexte. Par exemple,
32768au lieu du 256K par défaut. Cela économise des Go de VRAM.
- Optimisation Monoposte : Ajoutez
--max-num-seqs 1si vous l’utilisez seul. Cela réduit considérablement la surcharge de mémoire. Fini les séquences parallèles.
- Quantification : Utilisez
--quantization fp8(ou bitsandbytes pour 4 bits). C’est si votre GPU le supporte. Cela permet d’intégrer des modèles plus grands dans une VRAM plus petite.
4. Interaction avec le Modèle
Le serveur tourne sur
http://localhost:8000. Vous envoyez des requêtes via cURL. Ou le SDK Python d’OpenAI.
Exemple de Requête cURL :
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [{"role": "user", "content": "Explique l'intrication quantique."}],
"temperature": 0.7
}'5. Gestion des Entrées Multimodales
Pour le traitement d’images, configurez le budget de tokens. C’est pour la vision dynamique. Cela équilibre vitesse et détail.
- Détail Standard :
--mm-processor-kwargs '{"max_soft_tokens": 280}'(Par défaut)
- Détail Élevé :
--mm-processor-kwargs '{"max_soft_tokens": 1120}'
Le support audio natif est exclusif. C’est pour les modèles Gemma 4 E2B et E4B. Dans vLLM, la pipeline vLLM-Omni gère cela. Elle permet à ces modèles Edge de traiter la parole. Pour la reconnaissance ou la traduction.
1. Lancement du Serveur Audio-Enabled
Pour l’audio, servez l’un des modèles “Effective” Edge. Utilisez le flag
--trust-remote-code. Cela garantit le chargement des connecteurs multimodaux.
# Servir le modèle 4B Edge avec support audio
vllm serve google/gemma-4-E4B-it \
--trust-remote-code \
--max-model-len 32768 \
--limit-mm-per-prompt '{"audio": 1}'2. Préparation de Vos Données Audio
Gemma 4 attend un format technique spécifique. Pour un traitement optimal.
- Format : Forme d’onde mono-canal, 16 kHz float32.
- Normalisation : Les échantillons doivent être échelonnés. Entre [-1, 1].
- Durée : Les clips jusqu’à 30 secondes sont supportés.
- Coût en Tokens : Chaque seconde d’audio consomme 25 tokens.
3. Envoi d’une Requête Audio
Vous interagissez avec le serveur. Utilisez un format compatible OpenAI. Pour les entrées multimodales. Placez le contenu audio avant le texte. Cela améliore la performance.
Extrait Python Exemple :
import base64
import requests
Encodez votre fichier WAV mono 16kHz en base64
with open("speech.wav", "rb") as f:
audio_base64 = base64.b64encode(f.read()).decode("utf-8")
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "google/gemma-4-E4B-it",
"messages": [
{
"role": "user",
"content": [
{"type": "audio_url", "audio_url": {"url": f"data:audio/wav;base64,{audio_base64}"}},
{"type": "text", "text": "Transcrivez cet audio et résumez le point principal."}
]
}
]
}
)
print(response.json()["choices"][0]["message"]["content"])4. Configuration Audio Avancée
Votre matériel est limité en ressources? Ajustez la gestion des fonctions audio par vLLM.
mm_processor_kwargs: Comme pour la vision, ajustez le budget de tokens. C’est pour les fonctions audio. Si la variante du modèle le supporte.
limit_mm_per_prompt: Utilisez-le au lancement. Cela empêche le modèle de traiter trop de fichiers audio à la fois. Cela économise de la VRAM.
LLM Updates — Muse Spark de Meta AI : Décryptage, Caractéristiques, Benchmarks, API et Accès
Gemma 4 vs Qwen 3.5 : Le Duel
Gemma 4 et Qwen 3.5 sont des familles open-weight très compétitives. Elles ont été lancées début 2026. Elles partagent des licences permissives (Apache 2.0). Leurs scores de raisonnement sont élevés. Mais elles divergent. Surtout en spécialisation multimodale. Et en efficacité architecturale. Le choix dépendra de vos priorités. Je trouve ça génial d’avoir autant de concurrence.
Comparaison de Haut Niveau
| Caractéristique | Gemma 4 (31B Dense) | Qwen 3.5 (27B Dense) |
|---|---|---|
| Force Principale | Raisonnement & Cohérence Logique | Codage & Compréhension Visuelle |
| Contexte Max | 256K tokens | 262K tokens (extensible à ~1M) |
| Architecture | Hybride (Fenêtre Coulissante + Attention Complète) | Hybride (Attention Linéaire + MoE Sparse) |
| Multimodalité | Texte, Image, Vidéo, Audio Natif (Edge) | Texte, Image, Vidéo (Flux Unifié) |
Différences Clés de Performance
- Logique & Raisonnement : Gemma 4 31B surpasse Qwen 3.5 27B. C’est dans la classification logique complexe. Et le raisonnement scientifique, comme GPQA Diamond (84.3%).
- Codage : Qwen 3.5 est souvent cité comme supérieur. Pour l’analyse technique. Et l’ingénierie logicielle. Il égale les modèles haut de gamme. Comme GPT-5-mini. Sur SWE-bench Verified (72.4%).
- Vision & Vidéo : Qwen 3.5 a une plus grande capacité de traitement de frames. Jusqu’à 280 images en tant que frames vidéo. Gemma 4 se concentre sur l’analyse d’images uniques très détaillées.
- Vitesse d’Inférence : L’attention linéaire de Qwen 3.5. Son MoE sparse. Souvent, cela se traduit par des temps de réponse plus rapides. C’est comparé à l’architecture plus dense de Gemma.
Notes sur l’Expérience Utilisateur
Les premiers retours de la communauté LocalLLaMA sont clairs. Gemma 4 semble plus naturelle. Surtout dans les conversations. Elle suit mieux les instructions complexes. C’est quand son mode de pensée est activé. Qwen 3.5 est loué. Il est un “all-rounder” plus robuste. Pour les questions techniques difficiles. C’est une question de préférence. Et d’usage.
Choisir entre Gemma 4 26B A4B et Qwen 3.5 35B MoE? La décision dépend de vous. Priorisez-vous la vitesse d’inférence brute? Ou une gestion de contexte massive? Voilà la question.
Les deux modèles utilisent une architecture Mixture-of-Experts (MoE). Ils ont un nombre total de paramètres élevé. Mais n’utilisent qu’une petite fraction. Pour chaque “pensée”. Cela réduit les coûts de calcul. C’est intelligent.
Comparaison des Spécifications MoE
| Caractéristique | Gemma 4 26B A4B | Qwen 3.5 35B MoE |
|---|---|---|
| Paramètres Totaux | 25.2 Milliards | 35.1 Milliards |
| Paramètres Actifs | 3.8 Milliards | 5.4 Milliards |
| VRAM (4-bit Q4) | ~15.6 Go | ~21.2 Go |
| Experts | 16 (2 actifs par token) | 64 (8 actifs par token) |
| Fenêtre de Contexte | 256K tokens | 1M+ tokens |
Le “Sweet Spot” Matériel
- Gemma 4 26B A4B : C’est le roi des cartes 16 Go de VRAM. Comme la RTX 4080. Ou la 4070 Ti Super. Elle n’active que 3.8 milliards de paramètres. Elle est incroyablement rapide. Souvent plus de 140 tokens/sec. Sur du matériel grand public. Elle s’y intègre bien. Avec de la place pour un tampon de contexte décent.
- Qwen 3.5 35B MoE : C’est un ajustement plus serré. Pour les cartes 24 Go de VRAM. Comme la RTX 3090/4090. Elle demande plus de mémoire. Mais son architecture à 64 experts la rend plus “savante”. Sur une plus grande variété de sujets de niche. Que la Gemma à 16 experts.
Nuances de Performance
- Efficacité : Le tuning A4B de Gemma 4 est très optimisé. Pour les étapes de “réflexion”. Elle effectue les tâches logiques. Presque aussi bien que sa sœur 31B Dense. Mais 4 fois plus vite.
- Contexte : Qwen 3.5 utilise un mécanisme d’Attention Linéaire. Il peut s’adapter à 1 million de tokens. Plus gracieusement que l’approche de fenêtre coulissante de Gemma. Vous conversez avec 10+ longs documents PDF à la fois? Qwen est le meilleur outil.
- Multilinguisme : Qwen 3.5 garde un léger avantage. Pour le codage non-anglais. Et la documentation technique. Gemma 4 est souvent préférée pour la prose anglaise créative. Et le suivi nuancé des instructions.
En Résumé : Lequel choisir?
Choisissez Gemma 4 26B si vous avez 16 Go de VRAM. Vous voulez l’assistant le plus rapide possible. Pour le codage et les tâches quotidiennes. Choisissez Qwen 3.5 35B si vous avez 24 Go de VRAM. Vous devez traiter des ensembles de données massifs. Ou des historiques de chat extrêmement longs.
Gemma 4 et OpenClaw : L’IA Agentique

Connecter Gemma 4 à OpenClaw localement? Utilisez l’intégration Ollama. Elle automatise la plupart des étapes. C’est simple et efficace.
1. Configuration Automatisée (Recommandé)
Ollama est déjà installé? Lancez OpenClaw. Configurez-le. Pour utiliser un modèle Gemma 4 spécifique. Une seule commande suffit.
ollama launch openclaw --model gemma4:26bQu’est-ce que cela fait? Il télécharge le modèle (s’il manque). Il démarre la passerelle OpenClaw. Et définit Gemma 4 comme votre modèle principal.
Variantes : Remplacez
26bpar d’autres tailles. Comme
e2b,
e4b, ou
31b. Cela dépend de votre matériel.
2. Configuration Manuelle
Vous préférez éditer votre fichier de configuration? OpenClaw utilise un fichier JSON5. Il est situé à
~/.openclaw/openclaw.json.
Téléchargez le modèle :
ollama pull gemma4:26bÉditez
openclaw.json: Ajoutez ou mettez à jour la section
agents. Pour pointer vers votre endpoint Ollama local :
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/gemma4:26b", // ID du modèle depuis Ollama
"fallback": "openai/gpt-4o-mini" // Fallback optionnel
}
}
}
}Redémarrez la Passerelle : Après avoir enregistré le fichier. Redémarrez votre service OpenClaw. Ou exécutez
openclaw restart. Pour appliquer les changements.
3. Conseils d’Optimisation Matérielle
- RAM/VRAM : Assurez-vous d’avoir assez de mémoire. Le modèle 26B MoE demande ~17 Go de RAM. La variante E2B fonctionne avec 4 Go.
- Fenêtre de Contexte : Les agents OpenClaw sont performants avec 64k tokens minimum. Gemma 4 supporte jusqu’à 256k. Limitez-le dans votre config. Cela économise de la mémoire.
- Recherche Web : Activez la recherche web pour les modèles locaux. Exécutez
ollama signindans votre terminal. Cela authentifie le plugin.
Le fichier
openclaw.jsonutilise le format JSON5. Il supporte les commentaires. Et les virgules de fin. Il définit le comportement de votre agent. Ses permissions. Dans OpenClaw 2026.3.2 et versions ultérieures. Les permissions des outils sont désactivées par défaut. Pour des raisons de sécurité. Vous devez les activer explicitement. Dans ce fichier.
Liens utiles pour OpenClaw :
Schéma Complet openclaw.json pour Gemma 4
Cette configuration active l’accès complet aux outils. Elle connecte votre modèle Gemma 4 local. Via Ollama.
{
"$schema": "https://docs.openclaw.ai/schema/openclaw.json", // Optionnel : ajoute l'autocomplétion de l'éditeur
"agents": {
"defaults": {
"model": {
"primary": "ollama/gemma4:26b", // Votre variante locale de Gemma 4
"fallback": "openai/gpt-4o-mini" // Fallback optionnel si le local échoue
},
"tools": {
"profile": "full", // Active tous les outils d'agent standard (web, shell, etc.)
"sessions": {
"visibility": "all" // Assure que les outils peuvent interagir avec toutes les sessions actives
},
"allowlist": [ // Autorise explicitement les commandes à haut risque
"npm",
"python",
"git",
"curl"
],
"ask": "once" // "always", "once" (par session), ou "off" (mode YOLO)
}
}
},
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434/v1", // Endpoint local Ollama par défaut
"api": "openai-completions" // Utilise l'API locale compatible OpenAI
}
}
}Composants de Configuration Critiques
tools.profile: "full": Essentiel pour la version 2026.3.2+. Sans cela, votre agent “parlera”, mais n’exécutera aucune action. C’est une sécurité importante.
tools.allowlist: Limite les commandes terminales que l’agent peut exécuter. C’est une couche de sécurité vitale. Surtout pour les agents locaux avec accès à l’hôte.
tools.ask: Contrôle l’exigence d’une “intervention humaine”. Le régler sur
"always"assure que l’agent demande la permission. Avant chaque exécution d’outil.
$schema: Inclure cette URL aide les IDE. Comme VS Code. Cela fournit une validation en temps réel. Et des infobulles.
Appliquer Vos Modifications
Enregistrez le fichier à
~/.openclaw/openclaw.json(ou
%USERPROFILE%\.openclaw\openclaw.jsonsous Windows).
Validez votre configuration. Pour les erreurs de syntaxe :
openclaw doctorRedémarrez la passerelle. Pour appliquer les permissions :
openclaw gateway config.applyGemma 4 sur Hugging Face : Votre Accès Facile
La famille de modèles multimodaux Gemma 4. Elle a été lancée par Google DeepMind. C’était le 2 avril 2026. Elle est disponible sur Hugging Face. Sous la licence open-source Apache 2.0. C’est une excellente nouvelle pour la communauté.
Disponibilité sur Hugging Face
Vous trouvez la collection officielle Google Gemma 4. Elle inclut les variantes de base (pré-entraînées). Et celles “instruction-tuned” (-it). Pour les quatre tailles de modèle.
google/gemma-4-E2B-it: Petit modèle multimodal (~2.3B paramètres effectifs). Pour mobile et appareils Edge. Supporte texte, image, et entrée audio native.
google/gemma-4-E4B-it: Modèle Edge moyen (~4.5B paramètres effectifs). Supporte texte, image, et audio natif.
google/gemma-4-26B-A4B-it: Modèle Mixture-of-Experts (MoE) haute efficacité. Avec 3.8B paramètres actifs. Supporte texte et images.
google/gemma-4-31B-it: Modèle dense puissant. Pour un raisonnement de haute qualité. Et des performances de serveur. Supporte texte et images.
Versions Communautaires et Optimisées
Plusieurs organisations communautaires ont déjà publié des formats optimisés. Sur la plateforme.
- Unsloth : Fournit des versions GGUF et 16 bits. Pour une inférence locale plus rapide. Ils sont très efficaces.
- NVIDIA : Offre le modèle 31B-IT-NVFP4 quantifié. Spécifiquement optimisé. Pour le matériel NVIDIA. C’est une performance max garantie.
Comment Utiliser via Transformers
Chargez un modèle Gemma 4. Utilisez la bibliothèque
transformers(v5.5.0 ou ultérieure requise). Suivez ce modèle :
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-E2B-it"
Chargez le processeur et le modèle
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
dtype="auto",
device_map="auto"
)Optimisez Gemma 4. Pour une VRAM plus faible. Utilisez la quantification 4 bits. Via la bibliothèque
bitsandbytes. Ou téléchargez des versions pré-quantifiées. Directement depuis Hugging Face.
1. Quantification de Gemma 4 avec Bitsandbytes
Quantifiez n’importe quel modèle Gemma 4. À la volée. Pendant son chargement dans votre environnement local. C’est la méthode la plus courante. Pour exécuter de plus grands modèles. Comme la variante 31B Dense. Sur des GPUs grand public.
Prérequis :
transformers >= 5.5.0bitsandbytesaccelerate
Implémentation du Code :
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
Configurez la quantification 4 bits
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="bfloat16",
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True
)
Chargez le modèle quantifié
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-4-31B-it",
quantization_config=quant_config,
device_map="auto"
)2. Versions Communautaires Pré-Quantifiées
Gagnez du temps et de la bande passante. Plusieurs organisations communautaires proposent des poids pré-quantifiés. Dans des formats comme GGUF (pour CPU/Ollama). Ou EXL2 (pour une inférence GPU rapide).
- Unsloth : Offre des versions GGUF et MLX de toutes les tailles de Gemma 4. E2B, E4B, 26B, 31B. Elles sont hautement optimisées. Pour Linux/Windows. Et Apple Silicon.
- NVIDIA : Fournit des checkpoints NVFP4 (point flottant 4 bits). Ils sont spécialement réglés. Pour une performance maximale. Sur les GPUs Blackwell et Ada Lovelace.
3. Fine-Tuning de Gemma 4 avec QLoRA
Créez votre propre version spécialisée. QLoRA (Quantized Low-Rank Adaptation) est la voie recommandée. Cette technique permet de fine-tuner le modèle. Avec beaucoup moins de VRAM. Le modèle de base reste en 4 bits. Seules de petites couches “adaptatrices” sont entraînées.
- Stratégie MoE (26B) : Pour le modèle Mixture-of-Experts. Utilisez un rank LoRA plus petit. Par exemple, 8 ou 16. Cela évite de submerger le routeur.
- Tâches de Vision : Fine-tunez pour la compréhension d’images? Vous aurez besoin de la bibliothèque
timm. Pour gérer les poids de l'encodeur de vision.
Plus d’infos sur Gemma 4 et ses variantes sur Hugging Face :