Je suis là pour vous guider à travers le monde des TPU (Tensor Processing Units). Ces puces, conçues par Google, transforment le calcul de l’IA. Elles accélèrent les tâches d’apprentissage automatique. Finis les goulots d’étranglement mémoire. Les TPU excellent dans les multiplications matricielles massives. Elles sont le cœur des réseaux neuronaux modernes. Imaginez un chef d’orchestre numérique pour l’IA. C’est exactement ce qu’elles sont.
Les TPU sont des circuits intégrés spécifiques. Ils diffèrent des CPU ou des GPU. Leur conception vise l’efficacité maximale pour l’IA. Grâce à eux, nous entraînons des modèles géants. Pensez à Gemini ou PaLM. Ces modèles n’existeraient pas sans cette puissance. C’est un véritable bond en avant. Je trouve cela fascinant.
Qu’est-ce qu’une TPU ?

Une Tensor Processing Unit (TPU) est un circuit intégré spécialisé. Google l’a créé. Son but est d’accélérer l’apprentissage automatique (ML) et l’intelligence artificielle (IA). Elle gère les opérations matricielles et tensorielles massives. Elle fait cela de manière rapide. Les TPU se distinguent des CPU ou GPU classiques. Elles sont des ASIC. C’est un peu la baguette magique de l’IA.
Caractéristiques Clés et Architecture
L’architecture d’un TPU est unique. Elle gère le calcul répétitif des réseaux neuronaux. Elle est plus efficace qu’un processeur généraliste. Elle excelle dans la multiplication matricielle.
- Conception en Réseau Systolique : J’adore cette idée. Les données circulent à travers une grille d’unités. C’est comme le sang dans un cœur. Cela réduit les accès constants à la mémoire. Des milliers d’opérations se déroulent par cycle d’horloge. Cette méthode économise de l’énergie.
- Unité de Multiplication Matricielle (MXU) : C’est le cœur de la puce. Une MXU traite des milliers d’opérations. Elle travaille en parallèle. Ce matériel est fait pour le calcul 2D du deep learning. Il est très rapide.
- Mémoire à Haute Bande Passante (HBM) : Les TPU utilisent la HBM. Elle assure un flux de données énorme. Cela évite que le processeur n’attende. L’inactivité est coûteuse.
- Formats de Données Spécialisés (bfloat16) : Le bfloat16 est une invention des TPU. Il utilise 16 bits. Il a la portée d’un float 32 bits. Cela signifie plus de vitesse, moins de mémoire. La précision reste suffisante pour l’entraînement.
- Interconnexion et TPU Pods : Les TPU peuvent être liés. Ils forment un “TPU Pod”. Ils utilisent un Interconnect (ICI) rapide. Des milliers de puces agissent alors comme un superordinateur unique. Imaginez la puissance de calcul !
Les TPU trouvent des applications partout. Elles traitent des tâches exigeantes. Cela inclut les calculs matriciels massifs. Elles aussi gèrent l’IA à faible latence en périphérie.
Qu’est-ce que le Bfloat16 ?
Le bfloat16 (Brain Floating Point 16-bit) est un format numérique. Google Brain l’a développé. Il accélère l’entraînement et l’inférence en IA. C’est un format de 16 bits. Il équilibre précision et vitesse.
Caractéristiques Clés
L’innovation du bfloat16 est sa répartition des bits. Elle diffère des formats 16 bits standards.
- Même plage que FP32 : Le bfloat16 utilise 8 bits d’exposant. C’est comme le FP32 standard (32 bits). Il représente des nombres très grands ou très petits.
- Moins de précision : La mantisse est réduite à 7 bits. C’est pour tenir dans 16 bits. Cela offre 2-3 chiffres décimaux de précision. C’est suffisant pour la plupart des tâches de deep learning.
Pourquoi c’est Important pour les TPU
Le bfloat16 est la “langue maternelle” des TPU. Il offre de nombreux avantages.
- Stabilité d’entraînement : Il évite les débordements numériques. Les nombres ne deviennent pas trop grands ou trop petits. C’est un problème courant avec le FP16.
- Pas de “Loss Scaling” : Le bfloat16 remplace souvent le FP32 directement. Le FP16 nécessite des astuces logicielles.
- Efficacité matérielle : Un multiplicateur bfloat16 est plus petit. On peut y mettre plus de puissance de calcul.
- Économie de mémoire : Le bfloat16 réduit de moitié la mémoire. On peut entraîner des modèles deux fois plus grands. Ou utiliser une taille de lot double.
Aujourd’hui, le bfloat16 est un standard. Google TPUs, NVIDIA GPUs, Intel Xeon et AMD le supportent.
L’architecture en réseau systolique
L’architecture en réseau systolique est un design matériel. Elle traite les données par “pulsations”. Un peu comme un cœur qui pompe. Google l’a relancé pour les TPU. Il résout le “goulot d’étranglement mémoire”. Ce goulot ralentit les processeurs classiques.
Le Cœur du Design : Une Grille de Cellules
Un réseau systolique est une grille 2D massive. Elle contient des éléments de traitement (PE) simples. Chaque PE inclut un multiplicateur et un additionneur. C’est une unité “Multiply-Accumulate” (MAC). Il a aussi des registres locaux. Pas de compteur de programme complexe. Les cellules calculent dès l’arrivée des données. Elles poussent ensuite le résultat au voisin.
Comment les Données “Pulsent” à Travers le Réseau
Le mouvement des données est la clé. Dans une configuration “Weight Stationary” des TPU :
- Chargement des poids : Les poids du réseau neuronal sont préchargés. Ils restent stationnaires dans les PE.
- Flux des activations : Les données d’entrée (activations) entrent d’un côté. Elles circulent horizontalement.
- Sommes partielles : Chaque cellule multiplie son poids. Elle l’ajoute à une somme partielle. Le résultat est transmis vers le bas.
- Le Résultat : Les résultats finaux émergent du bas. Ils ont traversé toute la grille.
Pourquoi c’est Plus Rapide pour l’IA
Le réseau systolique est plus efficace. Il surpasse les architectures traditionnelles. Je pense aux CPU (Von Neumann) ou GPU (SIMT) pour le calcul matriciel.
| Caractéristique | Von Neumann (CPU) | Réseau Systolique (TPU) |
|---|---|---|
| Mouvement des données | Récupéré de la mémoire pour chaque instruction. | Se déplace entre cellules adjacentes sur des fils courts. |
| Accès mémoire | Fréquent et lent (le “goulot d’étranglement”). | Les données sont lues une fois, utilisées des milliers de fois. |
| Logique de contrôle | Complexe (branchement, exécution hors ordre). | Minimale ; le flux de données est câblé et prévisible. |
| Énergie | Coût élevé dû au trafic constant du bus mémoire. | Coût faible ; la majeure partie de l’énergie va au calcul réel. |
Dans un Cloud TPU v3, chaque puce a deux unités. Chacune contient un réseau systolique 128×128. Cela représente 16 384 cellules. Cette grille dense permet des milliers d’opérations par cycle. C’est pourquoi les TPU entraînent des modèles massifs en jours. D’autres matériels prendraient des semaines.
Générations et Évolution des TPU
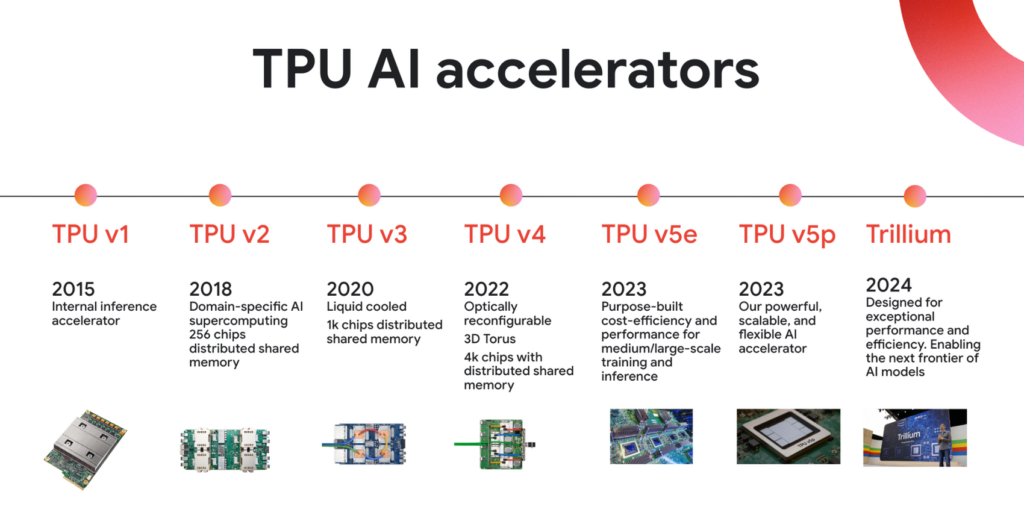
L’évolution des TPU de Google est impressionnante. Elle s’étend sur sept générations. Elle va des moteurs d’inférence simples aux superordinateurs IA refroidis par liquide. Chaque génération a apporté des percées. Cela concerne la performance, la précision et la mise en réseau.
| Génération | Lancement | Objectif Principal | Saut Architectural Notable |
|---|---|---|---|
| TPU v1 | 2015 | Inférence uniquement | Utilise un réseau systolique 8 bits. Efficacité 30x–80x supérieure aux CPU/GPU. |
| TPU v2 | 2017 | Entraînement + Inférence | Supporte le bfloat16 et les Interconnexions Inter-Puces (ICI) pour la mise à l’échelle des pods. |
| TPU v3 | 2018 | Mise à l’échelle | Introduit le refroidissement liquide. Quadruple la taille des pods à 1 024 puces. |
| TPU v4 | 2021 | Connectivité | Introduit les Optical Circuit Switches (OCS) pour reconfigurer dynamiquement les topologies de pods. |
| TPU v5e/v5p | 2023 | Spécialisation | Divisé en v5e (inférence économique) et v5p (performance maximale pour l’entraînement de Gemini). |
| TPU v6 | 2024 | Performance | “Trillium” double la capacité et la bande passante HBM. Offre 4,7x la puissance de calcul de la v5e. |
| TPU v7 | 2025 | Ère de l’Inférence | “Ironwood” supporte nativement le FP8. Propose des superpods massifs de 9 216 puces. |
Tendances Architecturales Majeures
- Évolution de la précision : Les premières TPU utilisaient des entiers 8 bits. C’était pour l’efficacité. Google Brain a développé le bfloat16. Il stabilise l’entraînement. La TPU v7 supporte le FP8 natif. C’est pour l’inférence à haut débit.
- Mise en réseau et mise à l’échelle : La mise en réseau a évolué. Elle est passée des designs toroïdaux 2D aux topologies 3D avancées. L’intégration des Optical Circuit Switches est une révolution. Google peut contourner les puces défectueuses. Il reconfigure les clusters sans recâblage physique.
- Cœurs spécialisés : À partir de la v4, Google a ajouté les SparseCores. Ce sont des matériels dédiés. Ils gèrent des tables d'”embedding” massives. On les trouve dans les systèmes de recommandation. Ils sont aussi dans les grands modèles linguistiques (LLM).
Évolution Grand Public et Périphérie
Google a adapté la technologie TPU. Elle dépasse les centres de données.
- Edge TPU (Coral) : C’est un ASIC à faible consommation. Il exécute les modèles TensorFlow Lite. Il fonctionne sur des appareils locaux.
- Google Tensor : C’est un système sur puce (SoC) personnalisé. Il équipe les smartphones Pixel. Il intègre la technologie Edge TPU. Il gère les tâches d’IA sur l’appareil. La photographie en est un exemple.
Comparaison : TPU vs. GPU vs. CPU
En 2026, le calcul IA a trois voies distinctes. Chacune est optimisée. Elles ciblent une partie spécifique du pipeline de développement.
| Caractéristique | CPU (Central Processing Unit) | GPU (Graphics Processing Unit) | TPU (Tensor Processing Unit) |
|---|---|---|---|
| Rôle Principal | Le “Chef de projet” pour la logique générale et l’orchestration système. | L'”Équipe Spécialisée” pour le calcul parallèle polyvalent. | L'”Usine Automatisée” pour le calcul matriciel hyperscale. |
| Architecture | Quelques cœurs puissants pour les branchements complexes. | Des milliers de cœurs simples utilisant le SIMT (exécution parallèle). | ASIC personnalisé utilisant des réseaux systoliques pour un flux de données direct. |
| Flexibilité | La plus élevée : exécute tout logiciel, OS, ou langage de programmation. | Élevée : supporte presque tous les frameworks IA (PyTorch, TensorFlow, etc.). | Modérée : hautement optimisée pour JAX, TensorFlow et PyTorch/XLA. |
| Efficacité | Faible pour l’IA ; idéale pour le prétraitement des données et les tâches I/O. | Élevée pour les tâches parallèles ; gère une large gamme de modèles IA. | Performance-par-watt la plus élevée pour les opérations tensorielles massives. |
| Mise à l’échelle | Limitée au nombre de cœurs ou à la mise en réseau de serveurs individuels. | S’adapte à travers les nœuds via InfiniBand ou Ethernet haute vitesse. | Mise à l’échelle presque linéaire dans des “Pods” massifs. Jusqu’à 9 216 puces. |
Cas d’Utilisation
- Les CPU conviennent au prototypage initial. Ils sont bons pour l’apprentissage automatique traditionnel. Ils gèrent le prétraitement des données.
- Les GPU sont le choix par défaut. Ils servent à la plupart des entraînements de deep learning. Ils gèrent l’inférence à haut débit. Ils sont utiles pour divers outils.
- Les TPU entraînent des modèles à grande échelle. Ils exécutent l’inférence IA générative à grand volume. Le coût et l’efficacité énergétique sont importants.
Dans un pipeline de production, vous n’utilisez pas qu’une puce. Elles fonctionnent comme une équipe de relais spécialisée. Les données passent de l’une à l’autre. Chaque puce excelle dans sa tâche.
- Prétraitement des Données (le travail du CPU) : Les données brutes doivent être nettoyées. Le CPU gère ce “brassage” des données. Il lit les fichiers. Il décompresse. Il effectue des logiques complexes. Un TPU ou GPU serait perdu.
- Entraînement du Modèle (le travail du TPU) : Les modèles massifs privilégient l’efficacité et la vitesse. Le TPU utilise son réseau systolique. Il effectue les milliards de multiplications matricielles. C’est nécessaire pour entraîner les poids. Google utilise un TPU v6 Pod. Il entraîne la prochaine version de Gemini. Des interconnexions rapides permettent cela. Des milliers de puces travaillent ensemble.
- Ajustement Fin et Développement (le travail du GPU) : La flexibilité est essentielle. Elle est pour les ajustements plus petits. Ou pour diverses architectures de modèles. Le GPU “affine” un modèle pré-entraîné. Les GPU supportent de nombreuses bibliothèques. Ils gèrent aussi le code personnalisé.
- Inférence en Temps Réel (l’approche mixte) : Quand l’IA est utilisée, les puces collaborent.
- CPU : Reçoit l’entrée texte. Il vérifie la sécurité.
- TPU/GPU : Traite la requête. Il génère la réponse IA.
- Edge TPU/NPU : Un Edge TPU (dans un Google Pixel) gère le flou d’arrière-plan. Il fait aussi la traduction en direct. Pas besoin d’envoyer les données au cloud.
TPU v5p vs NVIDIA H100 : un duel au sommet
Le Cloud TPU v5p et le NVIDIA H100 sont des accélérateurs IA d’élite. Ils optimisent des objectifs différents. Le H100 domine en performance brute. Il est aussi polyvalent. Le TPU v5p vise l’efficacité d’entraînement à grande échelle. Il offre un excellent rapport qualité-prix.
Métriques de Performance Clés
- Débit brut : Le NVIDIA H100 offre un débit brut plus élevé par puce. Il atteint environ 1 979 TFLOPS. C’est en performance FP16. Le TPU v5p est à environ 459 TFLOPS (BF16).
- Vitesse d’entraînement LLM : Le H100 montre une légère avance. Environ 3 800 tokens/seconde/puce. Le TPU v5p est à environ 3 450.
- Capacité mémoire : Le TPU v5p offre plus de mémoire. Il a 95 Go HBM par puce. Le H100 standard a 80 Go.
Efficacité et Évolutivité
- Utilisation des FLOPs du modèle (MFU) : Le TPU v5p atteint une utilisation plus élevée (~58 %). Le H100 est à ~52 %. Cela concerne des charges de travail LLM spécifiques. C’est grâce à son exécution déterministe. Et son Inter-Chip Interconnect (ICI) rapide.
- Efficacité des coûts : Le TPU v5p est souvent plus économique. Il est meilleur pour les étapes de pré-entraînement longues. Il offre un rapport “Tokens par Dollar” 15-25 % supérieur. Il bat le H100.
- Consommation électrique : Les TPU sont plus économes en énergie. La variante v5e, plus légère, consomme beaucoup moins. Elle égale un H100 pour des tâches similaires.
Tableau Comparatif des Benchmarks
| Métrique | NVIDIA H100 | Cloud TPU v5p |
|---|---|---|
| FP16/BF16 de pointe | ~1 979 TFLOPS | ~459 TFLOPS (BF16) |
| Mémoire HBM | 80 Go | 95 Go |
| Bande passante mémoire | 2,0 To/s | 2,8 To/s |
| Entraînement approximatif (LLM) | ~3 800 jetons/sec/puce | ~3 450 jetons/sec/puce |
| Prix (GCP Approx.) | ~10 $ – 12 $ / heure | ~4 $ – 6 $ / heure |
Optimiser le code JAX pour Cloud TPU v5p
Pour optimiser le code JAX sur Cloud TPU v5p, il faut changer ses habitudes. Je dois passer à des modèles conscients du matériel. Ils maximisent le débit. Ils exploitent le réseau systolique et l’Inter-Chip Interconnect (ICI) rapide.
- Tirer parti du parallélisme multi-dimensionnel : Le TPU v5p est fait pour l’entraînement distribué. J’utilise Distributed Array (GDA) de JAX. J’utilise aussi
jax.jitavec des contraintes de sharding. Cela permet de monter en charge. - Maximiser l’utilisation du MXU : Le Matrix Multiply Unit (MXU) est la clé de la performance. Je dois le saturer. Les tailles de lot et les dimensions des caractéristiques doivent être des multiples de 128. Sinon, XLA ajoute du padding. Cela gaspille des cycles. J’utilise
dtype=jnp.bfloat16par défaut. Cela réduit la mémoire de moitié. C’est le format natif. - Minimiser les frais de compilation : La compilation JIT peut prendre des minutes. J’évite les formes dynamiques. XLA recompile à chaque changement de forme. J’utilise des séquences de longueur fixe.
- Profilage et débogage : Ne devinez pas le goulot d’étranglement. J’utilise le JAX Profiler et XProf. Je démarre une trace avec
jax.profiler.start_trace(). Je cherche les “Step Time”. Je vérifie si je suis “Compute-bound” ou “Memory-bound”. - Chargement efficace des données : Un TPU rapide peut facilement dépasser un chargeur de données lent. J’utilise la bibliothèque Grain. Elle est conçue pour le chargement rapide et déterministe. Je garde mes buckets Cloud Storage dans la même région que mon pod TPU. Cela maximise le débit. Cela minimise la latence.
Mise en œuvre du parallélisme tensoriel avec JAX
Pour le parallélisme tensoriel (TP) en JAX sur un TPU, j’utilise un Device Mesh. Il organise mes accélérateurs. Je définis ensuite un Sharding Spec. Il indique comment diviser mes données. Dans le paradigme SPMD (Single Program, Multiple Data) de JAX, le même code s’exécute sur chaque cœur TPU. Mais chaque cœur opère sur un “shard” différent du tenseur global.
Étapes de mise en œuvre
- Détecter les appareils disponibles : Je détecte d’abord les cœurs TPU.
import jax import jax.numpy as jnp from jax.sharding import Mesh, PartitionSpec as P, NamedSharding from jax.experimental import mesh_utils devices = jax.devices() - Créer le Device Mesh : J’organise les appareils en une grille logique. Pour un parallélisme tensoriel simple, je crée un maillage 1D. J’appelle l’axe ‘tp’.
# Créer un maillage 1D utilisant tous les appareils disponibles device_mesh = mesh_utils.create_device_mesh((len(devices),)) mesh = Mesh(device_mesh, axis_names=('tp',)) - Définir la stratégie de sharding : J’utilise
NamedSharding. JAX saura comment découper mes matrices. Pour le parallélisme tensoriel, je découpe la dimension des colonnes. Chaque appareil contient une tranche verticale.# P(None, 'tp') signifie : # - Dimension 0 (lignes) : Répliquée (None) # - Dimension 1 (colonnes) : Shardée sur l'axe 'tp' sharding = NamedSharding(mesh, P(None, 'tp')) - Initialiser les paramètres shardés : J’utilise
jax.device_put. Cela distribue l’array sur les cœurs TPU. Cela se fait à la création.key = jax.random.PRNGKey(0) weight_shape = (8192, 8192) # Créer des poids directement sur le TPU en bfloat16 weights = jax.device_put( jax.random.normal(key, weight_shape, dtype=jnp.bfloat16), sharding ) - Exécuter un calcul parallèle : J’encapsule ma fonction dans
jax.jit. Le compilateur XLA voit le sharding. Il insère les communications nécessaires. Cela garde le calcul correct.@jax.jit def sharded_matmul(x, w): return jnp.dot(x, w) # Si 'x' est répliqué et 'w' est shardé sur les colonnes, # la sortie 'y' sera automatiquement shardée sur les colonnes. output = sharded_matmul(input_data, weights)
Tableau récapitulatif : types de parallélisme dans JAX
| Type de Parallélisme | Utilisation de l’axe du Mesh | Modèle de Sharding | Avantage |
|---|---|---|---|
| Parallèle de Données | P(‘batch’, None) | Sharder uniquement la dimension du lot. | Mise à l’échelle simple pour les petits modèles. |
| Parallèle Tensoriel | P(None, ‘model’) | Sharder des dimensions de poids spécifiques. | Adapte les couches trop grandes pour une seule puce. |
| FSDP | P(‘fsdp’) | Sharder les poids, les gradients et l’optimiseur. | Efficacité mémoire maximale. |
Comment Accéder aux TPU
En 2026, vous pouvez accéder aux TPU de trois manières. Cela dépend de votre besoin. Un essai rapide, un grand cluster, ou des ressources gratuites ?
- Accès Gratuit et Rapide (Google Colab) : Google Colab est la porte d’entrée la plus simple.
- Comment y accéder : Ouvrez un notebook. Allez dans `Exécution > Changer le type d’exécution`. Sélectionnez `TPU`.
- Ce que vous obtenez : Vous avez généralement une TPU avec 8 cœurs. Ce sont des séries v2 ou v3. C’est gratuit. C’est parfait pour tester JAX ou TensorFlow.
- Services Cloud Professionnels (Google Cloud Platform) : Google Cloud TPU offre les dernières générations de TPU. J’utilise les v4, v5p, v6 “Trillium” et v7 “Ironwood”. C’est pour l’entraînement d’entreprise ou les grands modèles linguistiques. Consultez la documentation Google Cloud.
- Mise à disposition : Créez des VM TPU via la Google Cloud Console. Ou utilisez la CLI gcloud.
- Options de Tarification :
- À la demande : Payez à l’utilisation. Environ 1,20 $ par heure pour la v5e. Ou 4,20 $ pour la v5p.
- Spot TPUs : Jusqu’à 60-91 % moins chers. Google peut les reprendre à tout moment.
- Engagements : Des réservations d’un ou trois ans. Elles offrent des réductions importantes.
- Services gérés : Accédez aux TPU via Vertex AI (plateforme gérée). Ou via Google Kubernetes Engine (GKE). Cela gère la mise à l’échelle conteneurisée.
- Pour les Chercheurs (TPU Research Cloud) : Le programme TPU Research Cloud (TRC) offre un accès gratuit. Il s’adresse aux grands clusters TPU pour la recherche open source.
- Éligibilité : Ce programme est ouvert aux chercheurs. Aux étudiants et aux entrepreneurs aussi. Ils doivent partager leurs résultats. Cela se fait via du code open source ou des publications.
- Avantages : Les candidats acceptés obtiennent un accès temporaire et gratuit. Il s’agit de plus de 1 000 appareils Cloud TPU. Typiquement des générations v2 et v3.
- Matériel Local (Edge TPU) : J’achète du matériel Coral Edge TPU. C’est si j’ai besoin de la puissance TPU sur un appareil physique. Une caméra ou un robot, par exemple. Ce sont de petits modules à faible consommation. Ils sont disponibles en accélérateurs USB ou cartes PCIe. Ils exécutent les modèles TensorFlow Lite localement.
Utiliser un TPU dans Google Colab avec TensorFlow
Pour utiliser un TPU dans Google Colab, activez-le. Allez dans `Exécution > Changer le type d’exécution > Accélérateur matériel > TPU`. Une fois activé, connectez votre session Python au travailleur TPU distant. Voici un exemple de code TensorFlow. C’est la méthode la plus courante.
1. Initialisation et Configuration
Ce code boilerplate connecte votre notebook au cluster TPU. Il prépare la stratégie de distribution.
import os
import tensorflow as tf
# 1. Initialiser le TPU
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.TPUStrategy(tpu)
print("Running on TPU:", tpu.cluster_spec().as_dict()['worker'])
except KeyError:
print("TPU not found. Enable it in Runtime > Change runtime type")2. Exécuter un Simple Calcul
Utilisez strategy.scope() pour les opérations.
with strategy.scope():
a = tf.constant([[1.0, 2.0], [3.0, 4.0]])
b = tf.constant([[5.0, 6.0], [7.0, 8.0]])
c = tf.matmul(a, b)
print("Result:\n", c)3. Entraîner un Modèle (Keras)
Définissez et compilez les modèles Keras. Faites-le dans strategy.scope(). C’est pour l’accélération TPU.
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])Conseils pour les TPU Colab
- Taille de lot : Utilisez une taille de lot multiple de 8. Cela maximise les 8 cœurs TPU.
- Chargement des données : Utilisez Google Cloud Storage (GCS) pour le chargement rapide. Cela évite les goulots d’étranglement.
- Support JAX : J’initialise le TPU avec
jax.tools.colab_tpu.setup_tpu().
Utiliser PyTorch Lightning avec un TPU dans Google Colab
Pour utiliser PyTorch Lightning avec un TPU dans Google Colab, je change mon environnement d’exécution en TPU. Allez dans `Exécution > Changer le type d’exécution > TPU`.
1. Installation
En 2026, j’installe la bibliothèque XLA. C’est l’interface entre PyTorch et TPU. J’installe aussi la dernière version de Lightning.
!pip install cloud-tpu-client https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.13-cp38-cp38m-linux_x86_64.whl
!pip install lightning2. Définir Votre Modèle
J’configure mon LightningModule normalement. Pas besoin d’appeler .to(device) ou .cuda(). Lightning gère le placement du périphérique TPU automatiquement.
import torch
from lightning import LightningModule, Trainer
class MyLitModel(LightningModule):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return self.layer(x.view(x.size(0), -1))
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = torch.nn.functional.cross_entropy(logits, y)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)3. Initialiser l’Entraîneur
Pour exécuter sur le TPU, je règle accelerator="tpu". Je spécifie le nombre d’appareils (cœurs). Colab fournit généralement 8 cœurs TPU.
# Entraînement sur un seul cœur TPU
trainer = Trainer(accelerator="tpu", devices=1)
# Entraînement sur les 8 cœurs TPU (entraînement distribué)
# Note : Vous devrez peut-être redémarrer le notebook si vous changez le nombre de cœurs
trainer = Trainer(accelerator="tpu", devices=8)
model = MyLitModel()
# trainer.fit(model, train_dataloader)Considérations Clés
- Précision : Pour le bfloat16, je définis la variable d’environnement
XLA_USE_BF16=1. Ou je la configure dans le Lightning Trainer. Cela donne plus de vitesse et moins de mémoire. - Entraînement distribué : Avec
devices=8, Lightning utilise une stratégie DistributedDataParallel. Il réplique mon modèle sur chaque cœur. Il gère la communication des gradients. - Taille de lot : Les données sont divisées entre les cœurs. Le lot global doit être divisible par le nombre de cœurs (par exemple, 8). Cela évite l’inactivité matérielle.
Vous envisagez une reconversion professionnelle ?
Ou souhaitez-vous apprendre l’IA et le Machine Learning avec une méthodologie claire, structurée et rapide ?
Rejoignez nous chez DeepLearn Academy ! Nous proposons des formations e-learning adaptées aux professionnels, étudiants et ingénieurs.