Claude Opus 4.7 L’IA qui Code et Voit Tout, par seifeur guizeni — Claude Opus 4.7 est arrivé. C’est le modèle d’IA le plus avancé d’Anthropic. Il est disponible depuis le 16 avril 2026. Je le vois comme un véritable bond en avant. Il excelle en codage, en raisonnement et en perception visuelle.
C’est une sacrée mise à jour par rapport à Opus 4.6.
Claude Opus 4.7 : Ce qui Change Vraiment : Mes Premières Observations

Anthropic a mis le paquet. Voici les nouveautés qui m’ont marqué.
- Raisonnement Adaptatif et Niveaux d’Effort : Le modèle “pense” désormais de manière adaptative. Il décide de l’effort nécessaire. Dans l’API, nous pouvons régler ce niveau. Il va de “faible” à “xélevé”. Cela équilibre vitesse et intelligence.
- Vision Améliorée : C’est bluffant. Il prend en charge des images jusqu’à 2576px. Cela représente environ 3,75 MP. C’est trois fois plus qu’avant. Son acuité visuelle est incroyable. Analyser une capture d’écran ? Lire un schéma technique ? Plus aucun problème.
- Contexte et Sortie Massifs : Il gère un contexte d’un million de tokens. La sortie peut atteindre 128 000 tokens. Imaginez : générer des bases de code entières. Ou des documents très longs. Tout cela en une seule fois.
- Honnêteté Renforcée : Anthropic annonce un taux d’honnêteté de 92 %. Il y a moins d’hallucinations. La “flagornerie” – cette tendance à toujours être d’accord avec l’utilisateur – a fortement diminué. C’est un point clé pour la fiabilité.
Je le dis clairement : Opus 4.7 est le modèle le plus performant pour les tâches professionnelles, il est puissant. Seul le modèle restreint Claude Mythos, pour la cybersécurité, le surpasse sur certaines capacités spécifiques.
Performance et Disponibilité : Où le Trouver ?
Opus 4.7 est là. Il est déployé sur Claude.ai. On le trouve aussi sur la plateforme Claude. Il est intégré à Amazon Bedrock et GitHub Copilot. Son prix API reste le même qu’Opus 4.6. C’est 5 $ par million de tokens en entrée. Et 25 $ par million en sortie.
Les Louanges et les Griefs : Une Réception Mitigée
Les utilisateurs ont des avis partagés. Beaucoup adorent son “vibe coding”. Ils apprécient ses capacités d’ingénierie autonome. Mais certains signalent des régressions. Une sorte de “deux poids, deux mesures”, vous savez ?
- Consommation de Tokens : Des discussions sur Reddit et X (Twitter) évoquent un modèle “combatif”. Il consomme rapidement les limites de tokens.
- Suivi des Instructions : Des utilisateurs avancés signalent des problèmes. Le modèle ignore parfois des préférences de ton. Ou des benchmarks de récupération de contexte long. Il fait moins bien qu’Opus 4.6 sur ces points.
C’est comme une personnalité complexe. Brillant, mais avec ses humeurs.
Les Mises à Jour Techniques du Cœur
Claude Opus 4.7 vise l’autonomie. Il cible aussi la capacité visuelle. C’est pour le travail professionnel de la connaissance.
- Vision Haute Résolution : La résolution maximale a triplé. Elle atteint 2576px. Cela permet de lire les petits caractères. Les schémas techniques complexes sont analysés. Il peut même mapper les coordonnées au pixel près.
- Pensée Adaptative et Niveaux d’Effort : Les budgets de raisonnement manuel sont révolus. Le modèle décide en interne. Il juge combien de raisonnement est nécessaire. Un nouveau niveau “xhigh” (extra-élevé) a été ajouté. Il se situe entre “élevé” et “max”. Il est optimisé pour le codage complexe. Et pour la recherche agentique.
- Puissance de Génération Accrue : La fenêtre de contexte reste à 1 million de tokens. Mais il supporte maintenant 128 000 tokens en sortie. Cela génère des bases de code énormes. Ou des rapports très longs. Tout cela en un seul passage.
- Mémoire Améliorée : J’ai vu des progrès significatifs. La mémoire basée sur le système de fichiers est meilleure. Les agents peuvent conserver des “notes” fiables. Même sur des flux de travail longs, à plusieurs sessions.
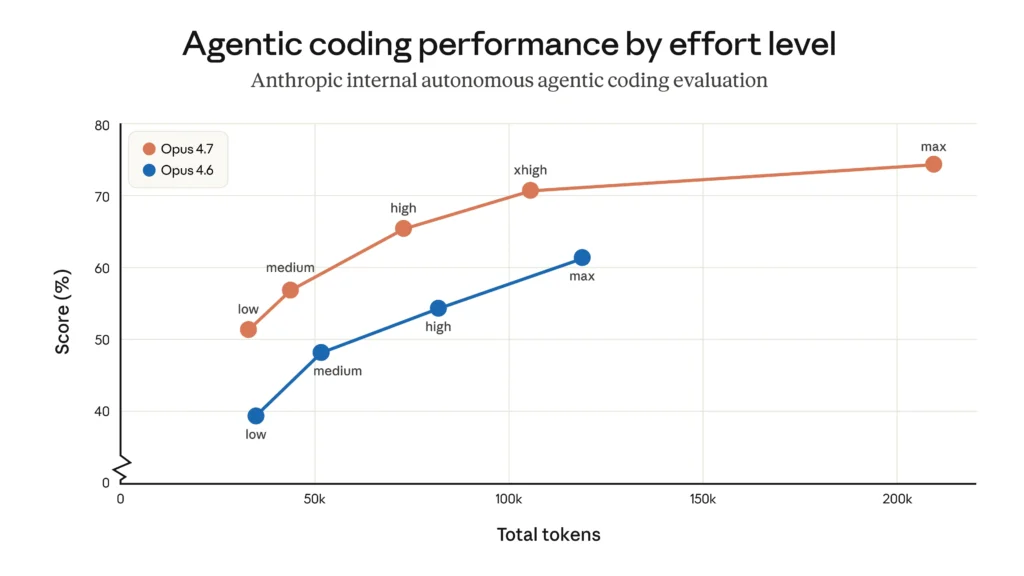
Gains de Performance Critiques : Des Chiffres qui Parlent
- Ingénierie Avancée : C’est un vrai “changement de paradigme” pour le codage. Il obtient 70 % sur CursorBench. C’était 58 % pour 4.6. Il résout trois fois plus de tâches de qualité production. Il le fait de manière autonome.
- Raisonnement Visuel : L’acuité visuelle a bondi de 54,5 % à 98,5 %. C’est presque la parité avec l’humain. C’est pour l’identification des détails visuels.
- Honnêteté et Fiabilité : Anthropic rapporte 91,7 % d’honnêteté. C’était 90,3 % pour Opus 4.6. Les hallucinations et omissions sont beaucoup moins nombreuses.
Contraintes et Changements Notables
- Suivi Littéral des Instructions : Le modèle ne lit plus entre les lignes. Il interprète les instructions strictement. Il faudra peut-être réajuster les prompts plus anciens et “lâches”.
- Nouveau Tokenizer : Un nouveau tokenizer est en place. Il peut augmenter le nombre de tokens de 1,0x à 1,35x pour le même texte. C’est par rapport à Opus 4.6. Cela augmente potentiellement les coûts. Même si le prix affiché est le même.
- Refus de Cybersécurité : C’est le premier modèle avec des protections automatiques. Il bloque les requêtes pour les exploits à haut risque. Les professionnels doivent utiliser le nouveau Programme de Vérification Cyber. C’est pour la recherche légitime en sécurité.
Benchmarks : La Précision d’Opus 4.7
Opus 4.7 a établi de nouveaux records. Il excelle dans le codage agentique et la vision. Il se maintient au même niveau que les meilleurs concurrents pour le raisonnement pur.
Opus 4.7 — Tableau de bord des performances
Résultats comparatifs sur 8 catégories de benchmarks. Données publiées par Anthropic.
Raisonnement documentaire
80,6%
+23,5 pts vs Opus 4.6
Navigation visuelle (haute rés.)
87,6%
+4,5 pts vs Opus 4.6
Travail de connaissance (Elo)
1 753
+134 pts vs Opus 4.6
Cohérence long terme
$10 937
+36,4% vs Opus 4.6
Raisonnement documentaire — OfficeQA Pro (% de réponses correctes)
Opus 4.7 dépasse les autres modèles de +23,5 pts minimum sur ce benchmark.
Raisonnement en long contexte — GraphWalks (1M tokens)
Progression de +17,4 pts sur BFS — la tâche la plus complexe algorithmiquement.
Codage — SWE-bench Multilingue & Multimodal (précision %)
| Modèle | Multilingue | Multimodal (interne) | Rang |
|---|---|---|---|
| Opus 4.7 | 80,5% | 34,5% | 1er |
| Opus 4.6 | 77,8% | 27,1% | 2e |
+7,4 pts sur le codage multimodal — une progression notable sur les tâches visuelles.
Raisonnement biomoléculaire — Biologie structurale (score %)
Travail de connaissance — GDPVal-AA (score Elo)
Progression de +140% en biologie structurale — le bond le plus spectaculaire entre les deux versions.
Comportements indésirables — fréquence (plus bas = meilleur)
Opus 4.7 réduit les comportements non alignés de 10,9% par rapport à Opus 4.6, et se situe juste après Mythos Preview.
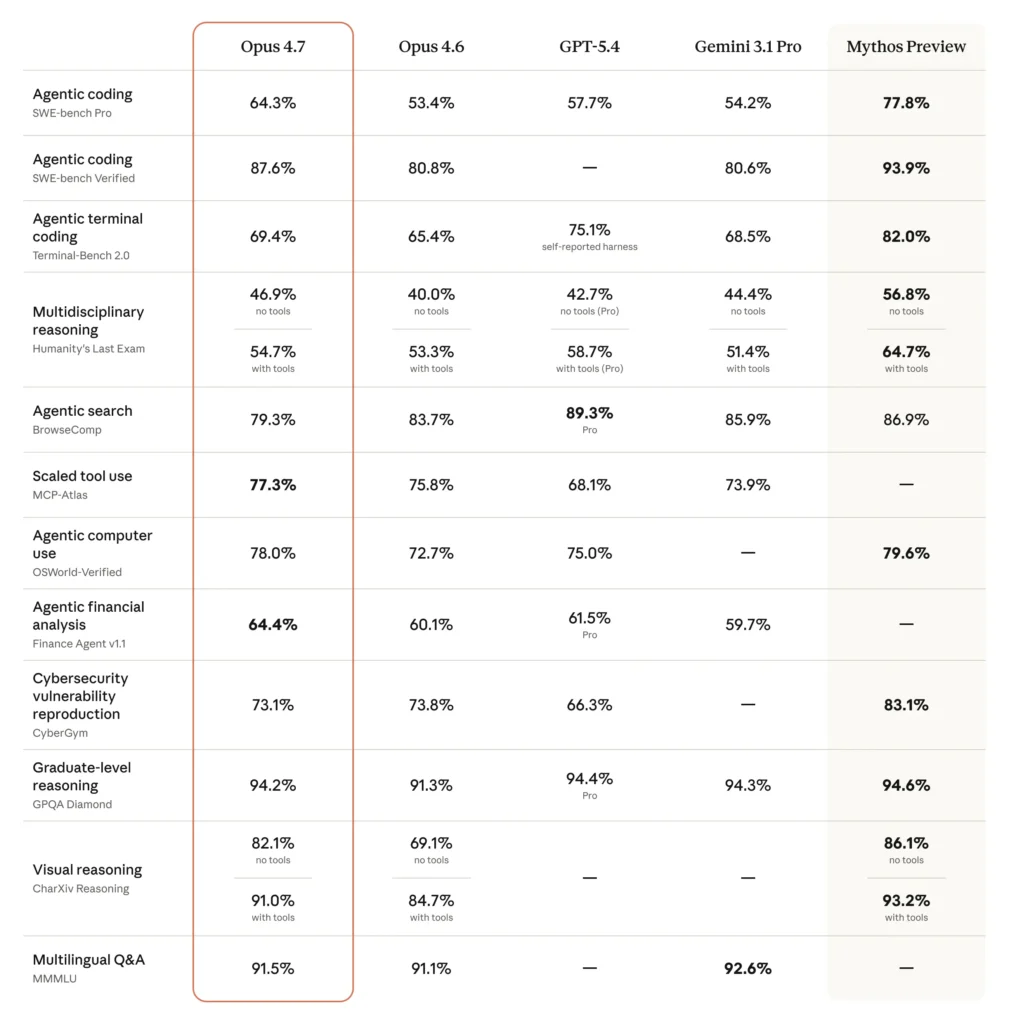
Principaux Benchmarks de Performance
Il surpasse souvent GPT-5.4 et Gemini 3.1 Pro dans les tests de production.
| Benchmark | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro (Codage Agentique) | 64,3% | 57,7% | 54,2% |
| SWE-bench Verified (Curration) | 87,6% | ~80,8% | 80,6% |
| MCP-Atlas (Utilisation d’Outils Scalée) | 77,3% | 68,1% | 73,9% |
| GPQA Diamond (Raisonnement de Doctorat) | 94,2% | 94,4% | 94,3% |
| GDPVal-AA (Travail de Connaissance) | 1753 (Elo) | 1674 | 1314 |
Gains Spécialisés
- Acuité Visuelle (XBOW) : Opus 4.7 a atteint 98,5 %. C’est grâce à sa résolution visuelle 3,3 fois supérieure. Elle était de 54,5 % pour Opus 4.6.
- Recherche Agentique (BrowseComp) : Ce modèle a régressé légèrement. Il est tombé à 79,3 %. Il est derrière GPT-5.4 Pro (89,3 %) et Gemini 3.1 Pro (85,9 %).
- Utilisation d’Ordinateur (OSWorld-Verified) : Il s’est amélioré à 78,0 %. Il réduit l’écart avec le Claude Mythos Preview restreint (79,6 %).
Améliorations Stratégiques
La fiabilité du modèle est sa force. Surtout pour les tâches à long terme. Il améliore de 14 % les workflows complexes. Il produit 75 % moins d’erreurs d’outils. Le nouveau niveau “xhigh” y contribue. Il offre un raisonnement plus profond. C’est pour le travail technique. Et il évite la latence extrême du réglage “max”.
Découvrez aussi — OpenAI GPT-5.5 : Décryptage Complet, Benchmarks, Coûts, Agents et Comparaison
Mon Guide Pratique pour Optimiser vos Prompts
Le retour utilisateur est mitigé. Voici mes stratégies. Elles vous aideront à tirer le meilleur d’Opus 4.7. Et à minimiser les soucis de coût et de “personnalité”.
1. Réduire la Verbosité et la Consommation de Tokens
Le nouveau tokenizer et la limite de sortie élevée peuvent rendre le modèle bavard. Utilisez ces contraintes dans votre prompt système. Ou au début de votre chat.
- Le “Flag Concis” : Ajoutez “Sois concis. Utilise des tableaux Markdown ou des listes à puces. Pas de fioritures conversationnelles. Pas de ‘certainement !’ au début.”
- La Contrainte “Sortie Directe” : Si vous avez besoin de code uniquement, écrivez : “N’affiche que le bloc de code brut. Pas d’explication. Sauf si je le demande spécifiquement.”
- Limitez votre Contexte : Opus 4.7 prend tout le contexte au pied de la lettre. Nettoyez l’historique de chat régulièrement. Cela évite que le modèle ne soit distrait.
2. Optimiser la “Pensée Adaptative”
Le mode “Pensée Adaptative” d’Opus 4.7 est puissant. Mais il peut être excessif pour des tâches simples. Si vous utilisez l’API, suivez ces règles.
| Complexité de la Tâche | Niveau d’Effort Suggéré | Pourquoi ? |
|---|---|---|
| Modifications simples / Chat | faible | Économise les tokens. Réponses quasi-instantanées. |
| Énigmes logiques / Maths | moyen | Équilibre précision et vitesse de réponse. |
| Refactoring de code | élevé | Essentiel pour mapper les dépendances entre fichiers. |
| Audits de sécurité | xélevé | Utilise le plus de calcul. Minimise les hallucinations dans la logique critique. |
Pour forcer une pensée plus profonde, utilisez des phrases comme : “Ce problème est plus difficile qu’il n’y paraît ; réfléchis attentivement et étape par étape avant de répondre“.
Pour réduire la latence : “Priorise une réponse rapide plutôt qu’une pensée profonde. En cas de doute, réponds directement“.
3. Corriger les Problèmes de “Littéralisme”
Vos anciens prompts (de 4.6 ou avant) échouent ? Vous devez être plus explicite.
Ancien style : “Corrige les bugs dans ce composant React.”
Optimisation 4.7 : “Analyse le composant React ci-joint pour les erreurs de gestion d’état et les problèmes de prop-drilling. Applique les corrections et fournis le composant mis à jour avec des commentaires expliquant les changements logiques.”
Modèle de Prompt Système “Mode Concis”
"Agis comme un expert technique senior. Suis ces règles pour toutes les réponses : Zéro Remplissage : Pas de 'Certainement,' 'Je comprends,' ou de transitions conversationnelles. Efficacité des Tokens : Utilise le chemin le plus direct vers la réponse. Utilise des listes à puces ou des tableaux pour les données. Littéralisme Strict : Si une question est ambiguë, demande des clarifications au lieu de deviner. Code-First : Pour les requêtes techniques, fournis d'abord le bloc de code, suivi d'un maximum de 3 points d'explication."
L’IA évolue vite. Gardez une longueur d’avance avec DeepSkill. La newsletter de référence sur l’IA dans le monde francophone.
Comparaison : Claude Opus 4.7 vs. OpenAI o1
Les deux modèles utilisent un “raisonnement interne”. Mais leur approche diffère grandement.
| Caractéristique | Claude Opus 4.7 (Adaptatif) | OpenAI o1 (Preview/Mini) |
|---|---|---|
| Style de Logique | Raisonnement Holistique : Pense “en une seule fois” mais peut varier l’effort. Plus fort sur le contexte large. | Chaîne de Pensée : Pensée explicite étape par étape. Plus fort en maths/physique de niveau doctorat. |
| Vitesse | Généralement plus rapide ; l’effort faible/moyen ressemble à un LLM standard. | Plus lent ; a une pause de “réflexion” obligatoire pour chaque requête. |
| Vision | Supérieure : Peut voir les détails fins (3.75MP) et coder directement à partir de maquettes d’interface utilisateur. | Modérée : A du mal avec les schémas techniques denses ou le texte minuscule. |
| Codage | Meilleur pour l’Architecture de Projet et le refactoring multi-fichiers. | Meilleur pour l’Optimisation d’Algorithmes et la logique mathématique complexe. |
Claude Code : L’Ingénieur Logiciel Autonome
Claude Code est mon outil CLI préféré. Il est conçu pour le codage agentique. Avec Opus 4.7, il a reçu sa plus grande mise à jour. C’est le 16 avril 2026 qu’il a franchi ce cap. Ce duo transforme le modèle. Il agit comme un ingénieur logiciel autonome. Il peut raisonner sur des bases de code entières. Il corrige les bugs complexes. Il vérifie son propre travail. Tout cela avec une supervision minimale.
Fonctionnalités Clés pour Claude Code
- Mode d’Effort xhigh : Claude Code utilise par défaut le niveau “xhigh”. Ce niveau est optimisé pour le codage agentique. Il est bien plus intelligent que le niveau “élevé”. Et il est plus efficace en tokens que le réglage “maximum”.
- Nouvelles Commandes Slash :
/ultrareview: Cette commande lance une analyse exhaustive. Elle recherche les bugs logiques profonds. Elle identifie les vulnérabilités de sécurité. Elle propose des améliorations architecturales./go: Une compétence d’automatisation. Elle demande à Claude de tester son travail de bout en bout. Il utilise des outils bash ou navigateur. Il simplifie le code. Il prépare une Pull Request automatiquement.
- Mode Auto pour les Utilisateurs Max : Les abonnés de niveau “Max” ont maintenant un “mode auto”. L’assistant peut effectuer des tâches de programmation complexes. Il les fait plus rapidement. Avec moins de permissions manuelles.
- Vérification Autonome : Opus 4.7 est plus honnête sur ses limites. Dans Claude Code, il effectue souvent des “preuves”. Il vérifie le code système. Il exécute ses propres tests. C’est avant de déclarer la tâche terminée.
Performances dans les Workflows de Codage
Opus 4.7 a étendu l’avance de Claude. Surtout dans les benchmarks d’ingénierie logicielle professionnelle.
- SWE-bench Pro : Il a résolu 64,3 % des problèmes GitHub réels. C’est un bond énorme par rapport aux 53,4 % d’Opus 4.6.
- CursorBench : Il a obtenu 70 %. C’est 12 points de plus que le modèle précédent. Il est bien meilleur pour le raisonnement créatif. C’est essentiel pour les refactoring à grande échelle.
- Terminal-Bench 2.0 : Le modèle a résolu plus de défis de codage spécifiques à la ligne de commande. Mais certains benchmarks montrent qu’il est légèrement derrière GPT-5.4. C’est pour des tâches de recherche CLI spécifiques.
Accès et Intégration
Opus 4.7 est déjà le défaut. C’est pour de nombreux utilisateurs de Claude Code. Il est intégré à Cursor et GitHub Copilot. C’est pour les niveaux Pro+ et Enterprise.
Les équipes utilisant Snowflake Cortex AI peuvent accéder à Opus 4.7. C’est directement dans leurs outils CLI. C’est pour construire des pipelines de production conscients des données.
Configuration d’Opus 4.7 dans Claude Code CLI
Pour commencer, assurez-vous que votre outil est à jour. Exécutez npm install -g @anthropic-ai/claude-code. Simple comme bonjour !
Configuration des Niveaux d’Effort
Opus 4.7 introduit le niveau “xhigh”. C’est maintenant le réglage par défaut dans Claude Code. C’est une sorte de “vitesse intermédiaire”. Elle offre un raisonnement plus profond que le réglage “élevé”. Mais sans la latence ou le coût en tokens du “max”.
- Commutateur Interactif : Tapez
/effortet appuyez sur Entrée. Un curseur apparaît. Utilisez les flèches pour choisir un niveau. - Commande Directe : Utilisez
/effort xhighpour le définir immédiatement. - Override Ponctuel : Lancez votre session avec
claude --effort max. C’est pour un raisonnement approfondi sur cette seule session. - Changement Permanent : Modifiez votre fichier
~/.claude/settings.json. Ajoutez"effortLevel": "medium"(ou votre niveau préféré). Cela l’appliquera globalement.
Nouvelles Commandes Slash
/ultrareview: Lance un examen parallèle. Plusieurs agents vérifient votre code. Ils détectent les bugs. Ils trouvent les problèmes architecturaux./model: Permet de basculer entre les modèles disponibles. Vous pouvez passer d’Opus à Sonnet. C’est pour les tâches plus simples. Cela économise votre budget de tokens.
Migration API de 4.6 à 4.7 : Mes Conseils
Passer votre intégration API d’Opus 4.6 à Opus 4.7 est facile. C’est une sorte de remplacement direct. Mais vous devrez ajuster quelques paramètres. C’est pour le nouveau tokenizer et les niveaux d’effort.
1. Mettre à Jour la Chaîne du Modèle
Changez votre identifiant de modèle. Utilisez le nouveau endpoint 4.7.
- API Anthropic :
claude-3-opus-20260416(ou l’aliasclaude-opus-4-7) - Amazon Bedrock :
anthropic.claude-3-opus-20260416-v1:0
2. Configurer les Niveaux de Pensée et d’Effort
Opus 4.7 introduit la Pensée Adaptative. Pour contrôler “l’intensité” de la réflexion du modèle, utilisez le nouveau bloc thinking dans votre requête.
{
"model": "claude-3-opus-20260416",
"max_tokens": 64000,
"thinking": {
"type": "enabled",
"budget_tokens": 16000,
"effort": "xhigh"
},
"messages": [...]
}
- Définissez un “Max Tokens” Élevé : Le raisonnement consomme votre budget de sortie. Assurez-vous que
max_tokensest au moins deux fois votrebudget_tokens. - Niveaux d’Effort : Utilisez “faible” ou “moyen” pour les tâches simples. C’est pour économiser de l’argent. Utilisez “xhigh” (la spécialité de 4.7) pour le codage complexe.
3. Tenir Compte de l’Inflation des Tokens
Le tokenizer 4.7 est plus granulaire. Le même texte produira 1,0x à 1,35x plus de tokens.
- Surveillance : Mettez à jour votre logique de surveillance d’utilisation. Une requête à 1,00 $ sur 4.6 pourrait coûter environ 1,25 $ sur 4.7.
- Limites de Taux : Vous pourriez atteindre plus rapidement la limite de Tokens Par Minute (TPM). Pensez à demander une augmentation si vous êtes proche du plafond.
4. Ajustements des Prompts : Le Correctif du “Littéralisme”
Opus 4.7 est plus littéral qu’Opus 4.6. Si vos prompts semblent “cassés” ou si le modèle est trop têtu :
- Soyez Explicite : Ne supposez pas que le modèle “devinera” votre intention. Définissez clairement le format de sortie. Par exemple : “Retourne SEULEMENT du JSON valide.”
- Prompts Système : Si le modèle est trop bavard, ajoutez : “Contrainte : Fournis la réponse immédiatement. Pas de fioritures conversationnelles. Pas de monologue interne.”
Tarification : Ce que Vous Devez Savoir
Claude Opus 4.7, lancé le 16 avril 2026, conserve le même prix catalogue qu’Opus 4.6. Pourtant, un nouveau tokenizer peut augmenter le coût effectif par requête jusqu’à 35 %. Soyez vigilant.
API et Tarification Standard
Les tarifs de base pour l’API Claude, Amazon Bedrock et Google Cloud Vertex AI sont identiques.
- Tokens d’Entrée : 5,00 $ par million de tokens.
- Tokens de Sortie : 25,00 $ par million de tokens.
- Mise en Cache des Prompts : Offre jusqu’à 90 % de réduction (0,50 $ par million de tokens).
- Traitement par Lots : Une réduction de 50 % pour les charges de travail asynchrones (2,50 $ en entrée / 12,50 $ en sortie par million de tokens).
- Inférence US-Only : Disponible avec une prime de 1,1x pour les charges de travail strictement domestiques.
L’Augmentation de Coût “Cachée”
Même avec un prix statique, deux facteurs peuvent augmenter vos factures.
- Nouveau Tokenizer : Opus 4.7 convertit le texte en 1,0x à 1,35x plus de tokens qu’Opus 4.6.
- Le texte en prose reste près de la base 1,0x.
- Le code, les données structurées (JSON/YAML) et le texte non-anglais atteignent souvent le multiplicateur 1,35x.
- Pensée Adaptative : Les niveaux d’effort plus élevés, comme “xhigh” ou “max”, produisent des traces de raisonnement plus approfondies. Cela consomme plus de tokens de sortie. Et c’est cinq fois plus cher que les tokens d’entrée.
Tarification Échelonnée pour les Contextes Longs
Des tarifs spécialisés s’appliquent pour les très grands prompts.
- Entrée de Prompt Long (>200K tokens) : 10,00 $ par million de tokens.
- Sortie de Prompt Long (>200K tokens) : 37,50 $ par million de tokens.
Pour mieux comprendre l’impact, j’ai simulé un coût. Imaginez refactoriser 5 000 lignes de code.
Un input de ~46 875 tokens et un output de ~2 750 tokens coûteraient environ 0,30 $ par requête. Le nouveau tokenizer ajoute 25-35 %. L’effort “xhigh” augmente le coût de sortie. Mais la mise en cache peut réduire le coût d’entrée de 90 % pour les tâches répétées.
Si Opus 4.7 est trop cher, Claude 3.5 Sonnet reste le champion du rapport qualité-prix. Il est 40 % moins cher. Mais il n’a pas la vision haute résolution d’Opus 4.7.
Claude Opus 4.7 sur Microsoft Foundry
Claude Opus 4.7 est disponible sur Microsoft Azure AI Foundry depuis le 16 avril 2026. Cette intégration est un atout majeur. Les équipes d’entreprise peuvent utiliser le modèle d’Anthropic. Il s’intègre à leur infrastructure Azure existante. Il hérite des contrôles de gouvernance, de sécurité et de conformité natifs.
Intégration et Fonctionnalités dans Foundry
- Gouvernance d’Entreprise : Chaque requête hérite des contrôles natifs d’Azure. Cela inclut Microsoft Entra ID pour l’identité. Le réseau privé via VNet est géré. Et il y a des pistes d’audit complètes via Azure Monitor.
- Chemin de Mise à Niveau Direct : Pour les équipes utilisant déjà Opus 4.6, c’est une mise à niveau fluide. Peu de changements sont nécessaires. C’est pour les chaînes d’outils ou les harnais de prompts existants.
- Support de la Pensée Adaptative : Foundry prend en charge le nouveau paramètre de pensée adaptative. Cela permet au modèle d’ajuster dynamiquement son effort de raisonnement. C’est basé sur la complexité de la requête.
- Facturation Unifiée : L’utilisation est facturée directement via votre abonnement Azure. Elle compte pour les accords MACC (Microsoft Azure Consumption Commitment).
Tarification sur Microsoft Foundry
La tarification suit le barème standard d’Anthropic. Mais les coûts réels sont gérés via l’Azure Marketplace.
- Tokens d’Entrée : 5,00 $ par million de tokens.
- Tokens de Sortie : 25,00 $ par million de tokens.
- Coût Effectif : Le nouveau tokenizer d’Opus 4.7 peut entraîner une augmentation de 35 % du nombre de tokens. C’est pour le même texte d’entrée. C’est par rapport aux versions précédentes.
Disponibilité et Régions
- Déploiement : Disponible en tant que type de déploiement “Global Standard” dans le catalogue de modèles d’IA.
- Régions : Actuellement actif dans “East US 2” et “Sweden Central”.
- Exigences d’Accès : Nécessite un abonnement Azure “Enterprise” ou “MCA-E” payant. Avec une méthode de paiement valide.
Prêt à passer au niveau supérieur avec l’IA ? Chez DeepLearn Academy, nous réinventons l’apprentissage en ligne. Profitez de nos modules courts et intensifs pour maîtriser le Machine Learning sans perdre de temps.