Claude-Mem : Le Cerveau Persistant pour Votre Code Claude
Je le vois si souvent : on travaille d’arrache-pied sur un projet, on résout un bug coriace, on intègre une nouvelle fonctionnalité majeure. Puis, la session se termine. Et là, c’est le drame. Claude, mon assistant IA, semble souffrir d’une amnésie totale. Il a tout oublié de nos discussions, des décisions architecturales, des particularités du code. On repart de zéro. C’est frustrant, et ça coûte cher en temps et en jetons.
C’est précisément ce problème que je cherche à résoudre avec Claude-Mem. C’est un plugin open-source que j’ai conçu pour donner à Claude Code une mémoire persistante et à long terme, transcendant les sessions.
Imaginez un assistant qui se souvient de chaque ligne de code, de chaque discussion technique, de chaque solution trouvée, jour après jour. Un véritable allié qui apprend avec vous.
Mes Promesses Clés : Fini l’Amnésie !
Avec Claude-Mem, votre expérience de développement se transforme. Voici ce que le plugin vous apporte :
- Archivage Automatique : Claude-Mem observe discrètement vos interactions terminales. Il enregistre les événements cruciaux, comme les corrections de bugs ou les implémentations de fonctionnalités, sans que vous n’ayez à lever le petit doigt.
- Injection de Contexte Intelligente : Lorsque vous démarrez une nouvelle session, il ne s’agit plus d’une page blanche. Le plugin parcourt sa base de données locale et injecte automatiquement le contexte historique le plus pertinent.
- Efficacité Redoutable en Jetons : J’utilise l’IA pour compresser les sorties d’outils en résumés concis. J’ai constaté des réductions d’utilisation de jetons allant jusqu’à 95 % pour les projets de longue haleine. C’est une économie substantielle, croyez-moi.
- Base de Connaissances Consultable : Vous pouvez interroger votre travail passé en langage naturel. “Quand avons-nous corrigé le bug de la base de données ?” est une question que Claude peut désormais répondre via une interface web locale ou la ligne de commande. C’est comme avoir un journal de bord interactif de votre projet.
Au Cœur du Fonctionnement de Claude-Mem
Notre système se positionne comme un intermédiaire intelligent entre votre terminal et l’IA Claude. Il observe, résume, puis stocke tout cela dans une base de données locale, prête à être récupérée à tout moment. C’est l’intelligence à votre service, sur votre machine.
1. La Boucle d’Observation : Chaque Interaction Compte
Alors que vous travaillez dans Claude Code, le plugin surveille chaque étape de votre session. Quand une tâche est achevée, ou qu’une session prend fin, il capture la sortie du terminal.
Ces journaux bruts sont ensuite envoyés à un “résumeur” – souvent un modèle plus petit ou une invite spécifique – pour extraire les faits essentiels : quel était le bug, quelle a été la correction, quelles dépendances ont été ajoutées.
Ces résumés deviennent des “Observations” stockées dans une base de données SQLite locale et un ChromaDB vector store.
2. L’Injection de Contexte : Le Démarrage Chaleureux
Normalement, Claude Code débute chaque session avec une ardoise vierge. Claude-Mem change cette dynamique. Avant même que vous ne tapiez votre première invite, le plugin interroge ma base de données locale pour les observations les plus récentes et les plus pertinentes. Il insère ensuite automatiquement un bloc “Mémoire” dans l’invite système de Claude.
Résultat ? Claude sait immédiatement ce sur quoi vous travailliez hier. Fini les explications répétées sur l’état du projet !
3. Le Flux de Récupération Progressif : Économiser des Jetons, Toujours
Pour préserver l’espace de la “fenêtre de contexte” (et votre portefeuille !), Claude-Mem ne déverse pas toutes les informations d’un coup. J’ai conçu une approche en couches :
- Couche 1 (L’Index) : Claude voit une liste de titres d’observations (par exemple, “Bug d’Auth Corrigé”, “Webhook Stripe Ajouté”).
- Couche 2 (Le Détail) : Si Claude a besoin de savoir comment le Webhook Stripe fonctionne, il utilise un outil intégré,
mem_get_detail, pour extraire le résumé complet de cet événement spécifique. - Couche 3 (Le Détail Complet) : Le contenu complet de l’observation n’est récupéré qu’à la demande explicite.
4. La Recherche Hybride : Sémantique et Mots-Clés
Le système utilise une recherche hybride pour dénicher les informations passées :
- Mots-Clés : Recherche des correspondances exactes (par exemple, “package.json”).
- Sémantique : Trouve des concepts. Si vous demandez “Comment gérons-nous les paiements ?”, il peut trouver des observations sur “Stripe” ou “Checkout” même si le mot “paiement” n’a pas été utilisé. C’est de la magie !
Composants Clés
Mon système repose sur quelques piliers techniques :
- Le Worker : Un processus en arrière-plan (
claude-mem-worker) qui gère les bases de données et l’interface utilisateur web. C’est le cerveau qui tourne en arrière-plan. - Le Plugin : Le code qui s’exécute à l’intérieur de Claude Code pour intercepter les messages et communiquer avec le worker.
- Vector DB (ChromaDB) : Utilisé pour “ressentir” le sens de vos requêtes.
- Relational DB (SQLite) : Employé pour stocker les données brutes et le texte. Tout reste local, je garantis votre vie privée.
Guide Étape par Étape pour Installer Claude-Mem
Je vais vous accompagner de l’installation à votre première session augmentée de mémoire. C’est simple, suivez-moi !
🛠️ Étape 1 : Installation du Worker
Le worker est le moteur en arrière-plan qui stocke vos données et exécute le tableau de bord local. C’est le cœur de la mémoire.
- Ouvrez votre terminal.
- Installez le worker globalement :
npm install -g @thedotmack/claude-mem-worker - Démarrez le worker (il utilise le port 37777 par défaut) :
claude-mem-worker start
Laissez cette fenêtre de terminal ouverte ou exécutez le worker en arrière-plan. Il est la clé de voûte de notre système.
🔗 Étape 2 : Configuration de Claude Code
Vous devez indiquer à Claude Code d’utiliser le plugin de mémoire que j’ai créé.
- Naviguez vers le dossier de votre projet.
- Installez le plugin (si ce n’est pas déjà fait) :
npm install @thedotmack/claude-mem - Lancez Claude Code en activant le plugin :
claude-code --plugin @thedotmack/claude-mem
📝 Étape 3 : Créez Votre Première Mémoire
Claude-Mem fonctionne mieux lorsqu’il a des “observations” à mémoriser. C’est la base de son apprentissage.
- Effectuez une tâche dans Claude Code (par exemple, “Créez un serveur Express basique”).
- Une fois terminé, dites à Claude : “Enregistre une observation sur cette configuration.”
Claude utilisera l’outil mem_save pour résumer le travail et le stocker. Intelligent, n’est-ce pas ?
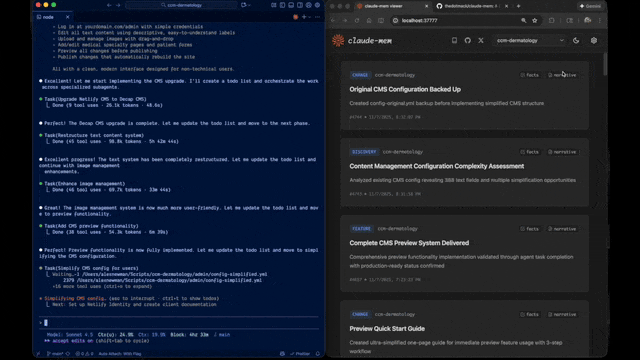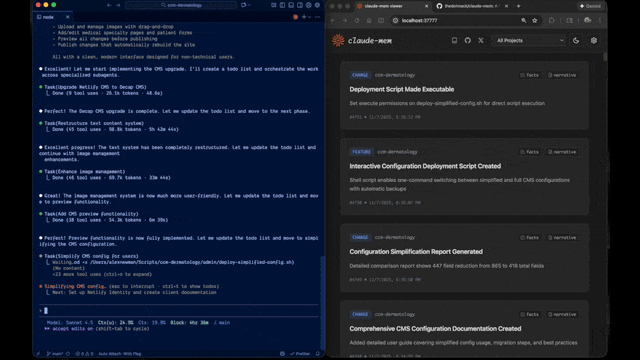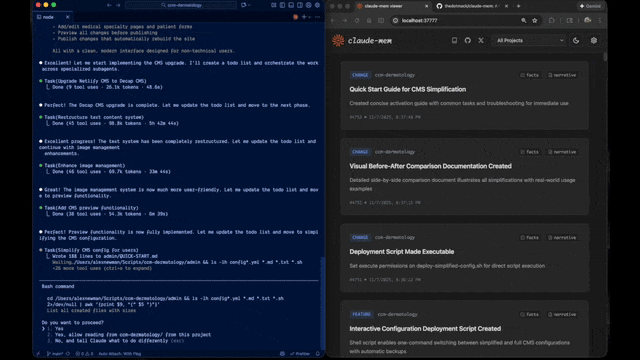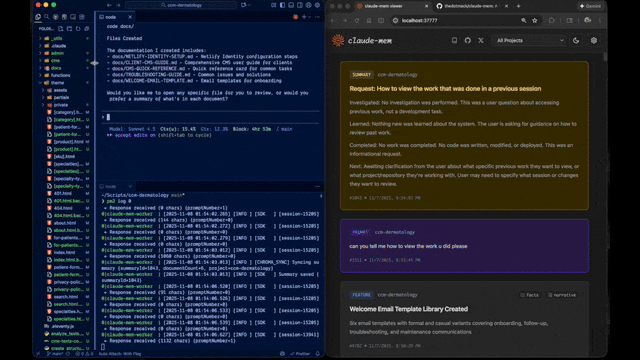
📂 Étape 4 : Accédez à l’Interface Web
Visualisez ce que Claude “retient” réellement. C’est votre fenêtre sur son cerveau.
- Ouvrez votre navigateur sur : http://localhost:37777
- Vous verrez une chronologie de vos sessions.
- Cliquez sur une entrée pour voir les Observations (les résumés compressés).
🔄 Étape 5 : Testez la Persistance
La “magie” opère lorsque vous démarrez une nouvelle session. C’est le moment de vérité !
- Quittez votre session Claude Code actuelle (
exit). - Démarrez une toute nouvelle session :
claude-code --plugin @thedotmack/claude-mem. - Demandez à Claude : “Sur quoi avons-nous travaillé la dernière fois ?”
Claude interrogera le worker et vous donnera un résumé de votre session précédente. Incroyable, n’est-ce pas ?
Pro-Tips pour Votre Usage Quotidien
- Sauvegardes Automatiques : Vous n’avez pas toujours besoin de demander. Le plugin enregistre souvent automatiquement lorsque vous terminez une tâche en plusieurs étapes.
- Confidentialité : Enveloppez les secrets dans
<private>VOTRE_CLÉ_ICI</private>pour qu’ils n’atteignent jamais la base de données. Votre sécurité est ma priorité. - Oublier : Si Claude est confus, accédez à l’interface web et supprimez les observations anciennes ou incorrectes. Vous gardez le contrôle.
Les Compétences de Claude-Mem : Comment Parler à Votre IA
Une fois le plugin actif, vous ne vous en tenez plus aux commandes terminal standard. Au lieu de cela, vous demandez à Claude d’utiliser ses nouvelles “compétences”. Il traduit votre langage naturel en appels d’outils spécifiques. C’est une interaction fluide et intuitive.
🔍 Recherche et Récupération
mem_search: Utilisez cette compétence pour trouver des sujets spécifiques à travers toutes les sessions passées. Demandez à Claude : “Recherche dans ma mémoire comment nous avons configuré la base de données.” Ou encore : “Trouve toutes les notes passées sur l’intégration Stripe.”mem_get_details: Utilisez celle-ci pour approfondir un index d’observation spécifique. Demandez à Claude : “Donne-moi les détails complets pour l’observation #5.”mem_get_timeline: Affiche une liste chronologique de ce qui s’est passé sur une période donnée. Demandez à Claude : “Montre-moi une chronologie de ce que nous avons fait hier.”
💾 Sauvegarde et Édition
mem_save: Force manuellement une entrée de mémoire si vous ne voulez pas attendre la sauvegarde automatique. Dites à Claude : “Enregistre une mémoire que nous avons décidé d’utiliser le Port 4000 pour le backend.”mem_set_project_context: Met à jour la vue d’ensemble “de haut niveau” de votre projet actuel. Dites à Claude : “Mets à jour le contexte du projet pour refléter que nous passons maintenant en production.”
🛠️ Gestion CLI (en dehors de Claude)
Exécutez ces commandes dans votre terminal habituel (où le worker est installé) pour gérer le moteur de mémoire lui-même :
| Commande | Action |
|---|---|
claude-mem-worker start | Démarre le serveur de mémoire et l’interface web. |
claude-mem-worker status | Vérifie si la base de données et le serveur sont actifs. |
claude-mem-worker stop | Arrête le processus en arrière-plan. |
claude-mem-worker clear | DANGER : Efface l’intégralité de votre base de données de mémoire. À utiliser avec grande prudence. |
💡 Pro-Tip : Si Claude dit qu’il “ne sait pas” comment chercher, rappelez-lui : “Utilise tes outils de mémoire pour chercher…” Cela l’incite à vérifier ses définitions d’outils disponibles. Parfois, il faut juste lui donner un petit coup de pouce.
Optimisation et Configuration Avancée de Claude-Mem
Ajuster la quantité d’informations que Claude extrait de sa mémoire est crucial. Je l’ai conçu pour éviter l’encombrement du contexte tout en vous fournissant le niveau de détail exact dont vous avez besoin. C’est une danse subtile entre information et efficacité.
⚙️ Modifier la Profondeur de Recherche
Vous pouvez contrôler cela via l’interface web ou en éditant directement le fichier de configuration.
1. Via l’Interface Web (Recommandé)
- Accédez à http://localhost:37777.
- Cliquez sur “Settings” (Paramètres) dans la barre latérale.
- Recherchez les paramètres “Search & Retrieval” (Recherche et Récupération).
- Ajustez le “Context Limit” (Limite de Contexte) : Augmentez-le pour voir plus d’observations passées à la fois ; diminuez-le pour économiser des jetons.
- Ajustez le “Similarity Threshold” (Seuil de Similitude) : Le diminuer rend la recherche plus “lâche” (plus de résultats) ; l’augmenter rend la recherche plus “stricte” (résultats de meilleure qualité).
2. Via le Fichier de Configuration
Le worker stocke les paramètres dans un fichier JSON (généralement dans votre répertoire personnel sous ~/.claude-mem/config.json). Jetez-y un œil !
max_observations: Définit le nombre d’extraits de mémoire injectés au début d’une session.summary_level: Peut être basculé entrebrief,standard, etdetailed.
🔎 Ajustements à la Volée
Vous pouvez également influencer la profondeur en formulant vos requêtes à Claude de manière spécifique :
- Pour des résumés de haut niveau : “Donne-moi un bref aperçu de nos trois dernières sessions de mémoire.”
- Pour des détails techniques approfondis : “Recherche dans ma mémoire la correction d’authentification et fournis tous les détails d’implémentation de l’observation sauvegardée.”
📊 Comprendre les “Couches”
Si Claude vous donne trop de “bla-bla”, rappelez-vous qu’il utilise un système à trois niveaux :
- Index : Juste les titres.
- Résumé : 1 à 2 paragraphes de ce qui s’est passé.
- Source : Le code ou les journaux réels (récupérés uniquement si vous demandez spécifiquement la “source complète”).
Maintenance et Dépannage
Si les choses semblent “stagnantes” ou si Claude manque des mises à jour récentes, utilisez ces étapes pour rafraîchir le système. Je vous guide pour garder votre assistant IA au top de sa forme.
🔄 Ré-indexation de la Base de Données
Parfois, l’index de recherche se désynchronise du texte réel. La ré-indexation force le worker à recalculer les liens de recherche. C’est un grand nettoyage.
- Arrêtez le worker :
claude-mem-worker stop - Exécutez la commande de ré-indexation :
claude-mem-worker index --force - Redémarrez :
claude-mem-worker start
🧹 Vider le Cache
Si Claude répète des informations anciennes et incorrectes, vous devrez peut-être vider le cache de session.
- Réinitialisation de Session : Simplement taper
exitdans Claude Code et redémarrer efface généralement le cache à court terme. - Suppression Manuelle d’Observation :
- Ouvrez http://localhost:37777.Trouvez l’entrée de mémoire “mauvaise”.Cliquez sur l’icône Corbeille/Supprimer.
🛠️ Corriger l'”Amnésie” (Aucun Résultat Trouvé)
Si Claude dit qu’il ne trouve rien, vérifiez ces trois points. Ce sont des erreurs courantes.
- Vérification du Statut : Exécutez
claude-mem-worker status. Si c’est “Offline”, le plugin ne peut pas communiquer avec la base de données. - ID du Projet : Assurez-vous d’être dans le même dossier. Claude-Mem associe souvent la mémoire au répertoire racine de votre projet.
- Vérification des Outils : Dans Claude Code, demandez : “À quels outils as-tu accès ?” Si
mem_searchn’est pas répertorié, le drapeau--pluginn’a pas été chargé correctement.
Pro-Tip : Si vous voulez un nouveau départ pour un projet spécifique sans supprimer toute votre histoire, vous pouvez archiver le fichier de base de données dans
~/.claude-mem/et laisser le worker en créer un nouveau.
Exportation et Partage de Vos Savoirs
Pour exporter vos souvenirs dans un fichier Markdown lisible, vous disposez de deux options principales : l’interface web ou une commande terminal. Je veux que vous puissiez partager ou sauvegarder votre progression facilement.
🖥️ Option 1 : Via l’Interface Web (La plus simple)
- Ouvrez votre navigateur sur http://localhost:37777.
- Accédez à l’onglet “Sessions” ou “Timeline”.
- Recherchez le bouton “Export” (généralement en haut à droite).
- Sélectionnez “Markdown” comme format.
Cela générera un fichier contenant tous vos résumés, classés par date et par session. C’est un journal de bord impeccable !
💻 Option 2 : Via la Commande Terminal
Le claude-mem-worker inclut un utilitaire d’exportation direct qui contourne le navigateur :
claude-mem-worker export --format markdown --output project_history.md--format: Choisissezmarkdown(par défaut) oujson.--output: Nommez le fichier comme bon vous semble.
📄 À Quoi Ressemble l’Exportation ?
Le fichier généré est structuré pour une lecture humaine et inclut généralement :
- En-têtes H1 : Dates et identifiants de session.
- En-têtes H2 : Titres d’observations individuelles.
- Puces : Les résumés compressés de ce qui a été réalisé.
- Métadonnées : Tags, chemins de projet et statistiques d’économies de jetons.
💡 Pourquoi Exporter ?
- Documentation : Transformez instantanément votre historique de codage en un
CHANGELOG.mdou un rapport d’avancement. - Intégration : Partagez le fichier
.mdavec un nouveau membre de l’équipe pour qu’il puisse voir l’évolution du projet. - Sauvegarde : Gardez une copie statique de vos “leçons apprises” au cas où vous effaceriez votre base de données locale.
Synchronisation Automatisée avec GitHub
Pour tenir votre équipe informée ou conserver un registre permanent, vous pouvez automatiser le processus de synchronisation vers votre dépôt GitHub. C’est une excellente pratique collaborative.
📂 Option 1 : La Synchronisation Automatique de CLAUDE.md
Claude-Mem dispose d’une fonctionnalité intégrée qui maintient un fichier CLAUDE.md à jour dans la racine de votre projet. Simple et efficace.
- Activer dans l’interface web : Accédez à http://localhost:37777 > “Settings”.
- Activer “Auto-update CLAUDE.md” : Lorsque c’est actif, chaque déclenchement de
mem_saveécrira également un résumé dans ce fichier. - Workflow Git : Puisque
CLAUDE.mdest un fichier local, il apparaîtra comme une modification dans votre statut Git. Vous pouvez le commettre comme n’importe quel autre code :git add CLAUDE.md git commit -m "docs: mise à jour de la mémoire du projet" git push
🤖 Option 2 : Synchronisation Automatisée via Git Hook (Avancé)
Si vous souhaitez pousser vos exportations de mémoire vers GitHub automatiquement à chaque fin de session, utilisez un hook Post-Commit. C’est pour les plus audacieux !
- Créez le hook : Dans votre projet, allez dans
.git/hooks/et créez un fichier nommépost-commit. - Ajoutez ce script :
#!/bin/bash # Exporter la dernière mémoire vers un dossier docs claude-mem-worker export --format markdown --output docs/MEMORY_LOG.md git add docs/MEMORY_LOG.md git commit --amend --no-edit - Rendez-le exécutable :
chmod +x .git/hooks/post-commit
📅 Filtrage des Exportations par Date
Si vous souhaitez exporter uniquement une période spécifique (par exemple, “les progrès de cette semaine”), utilisez les drapeaux --from et --to :
claude-mem-worker export --from 2023-10-01 --to 2023-10-07 --output rapport_hebdomadaire.md⚠️ Avertissement de Sécurité :
- Ne jamais synchroniser des données privées : Assurez-vous d’utiliser les balises
<private>pendant vos sessions.- Ignorer la Base de Données : Ajoutez
.claude-mem/à votre fichier.gitignore. Vous voulez synchroniser les exportations Markdown, pas les fichiers bruts de la base de données.
Exemple de CLAUDE.md
Le fichier CLAUDE.md est la manière standard de guider le comportement de Claude et d’enregistrer l’historique du projet. Si vous activez la fonction de mise à jour automatique, votre fichier ressemblera à ceci :
# Mémoire du Projet : [Nom du Projet]
## 🛠 Directives du Projet
* **Style** : Utilisez des modèles de programmation fonctionnelle.
* **Tests** : Exécutez `npm test` avant chaque commit.
* **Architecture** : Le backend utilise Express ; le frontend utilise Next.js.
---
## 📜 Activité Récente (Généré automatiquement)
### 2023-10-24 : Session #42
* **Corrigé** : Résolution de la condition de concurrence dans le middleware d'authentification.
* **Ajouté** : Intégration du Webhook Stripe pour les événements d'abonnement.
* **Note** : La chaîne de connexion à la base de données a été déplacée vers `.env.local`.
### 2023-10-22 : Session #41
* **Tâche** : Initialisation de la structure du projet et du pipeline CI/CD.
* **Observation** : Utilisation de `pnpm` au lieu de `npm` pour des installations plus rapides.🚫 Configuration du .gitignore
Pour éviter de divulguer l’intégralité de votre base de données de mémoire locale ou de gros fichiers binaires sur GitHub, ajoutez ces lignes à votre fichier .gitignore :
# Spécifique à Claude-Mem
.claude-mem/
claude-mem.db
claude-mem.log
*.vectorstore
# Infos sensibles (toujours une bonne pratique)
.env
.env.local
.secret🚀 Pro-Tip : La Commande “Memory Refresh”
Si vous constatez que
CLAUDE.mdest obsolète, vous pouvez forcer une mise à jour en disant à Claude : “Mets à jour le fichierCLAUDE.mdavec un résumé de nos progrès des trois dernières sessions.” Claude utilisera alors ses outilsmem_searchetwrite_to_filepour tout synchroniser instantanément. C’est rapide comme l’éclair !
Gestion Avancée de Projets et Personnalisation
Je crois fermement que Claude-Mem doit s’adapter à votre flux de travail, pas l’inverse. Je vais vous montrer comment gérer plusieurs projets simultanément et comment personnaliser les instructions de résumé pour que Claude parle vraiment votre langage.
Gestion de Projets Multiples
Claude-Mem est conscient du contexte. Il sépare généralement les souvenirs en fonction du répertoire racine où vous lancez claude-code. C’est astucieux !
- Séparation Automatique : Lorsque vous passez du Projet-A au Projet-B, le plugin détecte le changement de dossier. Il adapte sa mémoire.
- Profils de Projet : Vous pouvez consulter les chronologies spécifiques à chaque projet dans l’interface web (ici http://localhost:37777) en sélectionnant le chemin du projet dans le menu déroulant.
- Recherche Trans-Projets : Si vous voulez retrouver une solution utilisée dans un autre projet, vous pouvez demander : “Recherche dans tous les projets de ma mémoire le composant modal React que j’ai construit le mois dernier.”
Personnalisation des Instructions de Résumé
Vous pouvez dire à Claude comment rédiger ses souvenirs. C’est utile si vous souhaitez un ton spécifique (par exemple, très technique) ou un format (par exemple, uniquement des puces). C’est votre assistant, après tout.
- Ouvrez la configuration : Ouvrez
~/.claude-mem/config.jsondans votre répertoire personnel. - Éditez le champ
summary_prompt: C’est ici que la magie opère.
Exemple de Personnalisation
- Par défaut : “Résumer les changements effectués.”
- Personnalisé : “Résumer les changements à la manière d’un Changelog. Concentrez-vous sur les changements majeurs et les nouvelles variables d’environnement.”
🛠️ Configuration Globale vs. Locale
- Globale (
~/.claude-mem/config.json) : Paramètres qui s’appliquent à tous les projets sur lesquels vous travaillez. - Locale (
./.claude-mem.json) : Créez ce fichier dans un dossier de projet spécifique pour outrepasser les paramètres globaux (par exemple, un filtre de confidentialité plus strict pour un projet client).
Prompts Spécifiques
Selon que vous vous concentrez sur l’UI/UX ou l’architecture API, vous voudrez que Claude retienne différentes choses. Vous pouvez coller ces instructions dans votre summary_prompt dans config.json.
Prompt Orienté Frontend
Utilisez ceci si vous voulez que Claude priorise la structure des composants, le style et la gestion de l’état.
“Résume cette session en listant : Les nouveaux composants créés et leurs props. Les changements d’état global (Redux/Zustand). Les classes CSS/Tailwind spécifiques utilisées pour le thème. Tout point de rupture de conception réactive ajusté.”
Prompt Orienté Backend
Utilisez ceci si vous vous souciez de l’intégrité des données, de la sécurité et des performances.
“Résume cette session en listant : Les nouveaux points d’API et leurs payloads requis. Les modifications de schéma de base de données ou les migrations. Les nouvelles variables d’environnement ajoutées à .env. Les modifications de middleware (Auth, Logging, etc.).”
Prompt Minimaliste / Changelog
Utilisez ceci si vous voulez une chronologie claire et “sans fioritures”.
“Résume en utilisant le style Conventional Commits (feat, fix, docs, refactor). Pour chaque point, incluez le nom du fichier impacté. Gardez les descriptions sous 15 mots.”
Comment Appliquer Ces Prompts
- Ouvrez
~/.claude-mem/config.json. - Trouvez la clé “summary_instruction” ou “prompt_template”.
- Collez votre texte choisi entre les guillemets.
- Redémarrez le Claude-Mem Worker pour appliquer les modifications.
Correction Manuelle des Observations
Parfois, Claude résume une tâche de manière incorrecte. Vous pouvez corriger cela directement. Le contrôle est entre vos mains.
- Ouvrez l’interface web : Accédez à http://localhost:37777.
- Trouvez l’entrée : Utilisez la chronologie ou la barre de recherche pour trouver la mémoire spécifique.
- Éditez : Cliquez sur l’icône Crayon.
- Enregistrez : Corrigez manuellement le texte (par exemple, “En fait, nous avons utilisé le Port 5000, pas 4000”).
Claude utilisera désormais les informations corrigées dans les sessions futures. C’est votre manière d’enseigner.
📁 Lier les Configurations à des Projets Spécifiques
Si vous voulez le Prompt Frontend pour votre application React et le Prompt Backend pour votre API, voici comment faire :
- Naviguez vers le dossier de votre projet.
- Créez un fichier local : Nommez-le
.claudememrcouclaude-mem.json. - Ajoutez votre prompt spécifique au projet :
{ "summary_instruction": "Concentrez-vous sur les points d'API et les migrations de base de données." }
Résultat : Lorsque vous lancez Claude dans ce dossier, il écrase automatiquement vos paramètres globaux. C’est une flexibilité précieuse.
🐞 Débogage des Erreurs de Configuration
Si le worker ne démarre pas ou si le plugin ne se charge pas, ne paniquez pas !
- Vérification de la Syntaxe : Assurez-vous que votre JSON n’a pas de virgules de fin et utilise des guillemets doubles.
- Chemin d’Accès : Si vous avez déplacé le dossier
.claude-mem, le worker pourrait planter. Vous pouvez réinitialiser le chemin en exécutant :claude-mem-worker configure --db-path ./nouveau/chemin - Journaux : Vérifiez les journaux pour des erreurs spécifiques :
tail -f ~/.claude-mem/logs/worker.log
💡 Pro-Tip : La Commande “Oublier”
Si Claude est bloqué sur une ancienne version d’une idée, dites-lui : “Oublie tout ce qui est en mémoire concernant le nom-de-la-fonctionnalité-dépréciée.” Claude utilisera l’outil
mem_deletepour effacer ces entrées spécifiques pour vous. C’est une gomme magique !
Erreurs Courantes de Claude-Mem et Solutions
Même avec une configuration solide, vous pourriez rencontrer ces petits accrocs. Je vous donne mes astuces pour les résoudre rapidement.
🚫 1. “Plugin Introuvable” ou Outil Manquant
- Symptômes : Vous demandez à Claude de chercher dans la mémoire, et il répond : “Je n’ai pas d’outil pour ça.”
- Cause : Claude Code a été lancé sans le drapeau du plugin, ou le package n’est pas installé dans le répertoire actuel.
- Correction :
- Assurez-vous d’utiliser :
claude-code --plugin @thedotmack/claude-mem - Vérifiez l’installation :
npm list @thedotmack/claude-mem
- Assurez-vous d’utiliser :
🔌 2. Connexion Refusée (Port 37777)
- Symptômes : Message d’erreur disant “Échec de la connexion au worker” ou “ECONNREFUSED.”
- Cause : Le worker en arrière-plan ne fonctionne pas.
- Correction :
- Démarrez-le manuellement :
claude-mem-worker start - Vérifiez si le port est occupé :
lsof -i :37777(Si autre chose l’utilise, vous devrez tuer ce processus).
- Démarrez-le manuellement :
😵 3. Souvenirs “Hallucinés”
- Symptômes : Claude insiste sur le fait que vous avez fait quelque chose que vous n’avez pas fait, ou il utilise une logique de code ancienne, supprimée.
- Cause : Des observations de haute similitude mais obsolètes sont injectées dans le contexte.
- Correction :
- Supprimer : Utilisez l’interface web (localhost:37777) pour trouver et jeter l’ancienne observation.
- Clarifier : Dites à Claude : “Cette mémoire est obsolète. La nouvelle norme est [X]. Veuillez mettre à jour le contexte du projet.”
📄 4. Base de Données SQLite/Verrouillée
- Symptômes : Le worker plante ou n’enregistre pas de nouvelles observations.
- Cause : Plusieurs instances du worker essaient d’écrire dans la base de données en même temps.
- Correction :
- Arrêtez tous les workers :
claude-mem-worker stop - Tuez tous les processus fantômes :
pkill -f claude-mem-worker - Redémarrez :
claude-mem-worker start
- Arrêtez tous les workers :
📉 5. Débordement de la Fenêtre de Contexte
- Symptômes : Claude se plaint que le prompt est trop long ou commence à “oublier” le début de la conversation.
- Cause : Trop d’observations sont injectées au démarrage.
- Correction :
- Éditez votre
config.jsonet diminuez la valeur demax_observations(par exemple, définissez-la à 5 au lieu de 10). - Utilisez la méthode de “Divulgation Progressive” — demandez à Claude de ne vous montrer d’abord que les titres des mémoires.
- Éditez votre
🔍 Commande de Diagnostic Rapide
Si vous êtes bloqué, exécutez ceci pour voir exactement ce qui se passe sous le capot :
claude-mem-worker status --verbose
Réinitialisation d’une Base de Données Corrompue
Si le worker plante ou si les données ne sont pas sauvegardées, une “réinitialisation complète” est la solution la plus fiable. Attention, cela supprime votre historique.
- Arrêtez tous les processus :
claude-mem-worker stop pkill -f claude-mem-worker - Localisez et supprimez les fichiers de la base de données. Ils sont généralement dans
~/.claude-mem/.rm ~/.claude-mem/claude-mem.db rm -rf ~/.claude-mem/vector_store/ - Redémarrez le worker :
claude-mem-worker start
Le système recréera automatiquement des bases de données vides au démarrage. C’est un nouveau départ.
🎯 Optimisation des Résultats de Recherche
Si Claude affiche des souvenirs non pertinents, vous devez ajuster la “Sensibilité” de la recherche. C’est une question de réglage fin.
- Augmentez le seuil : Dans votre
config.json, trouvezmin_similarity_score.- Définissez-le à 0.8 pour une recherche “stricte” (uniquement des correspondances très pertinentes).
- Définissez-le à 0.5 pour une recherche “lâche” (inclut plus de correspondances “peut-être”).
- Utilisez des mots-clés spécifiques : Lorsque vous demandez à Claude de chercher, utilisez des termes de projet uniques.
- Mauvais : “Recherche le truc de connexion.”
- Bon : “Recherche l’implémentation du middleware d’authentification JWT.”
- Élaguez l’index : Si une session spécifique était une “impasse” (vous avez supprimé ce code), accédez à l’interface web et supprimez cette session afin que ses observations ne polluent plus vos résultats de recherche.
⌨️ Raccourcis Clavier de l’Interface Web
Naviguer dans le tableau de bord local (http://localhost:37777) est plus rapide avec ces raccourcis :
Shift + /: Ouvre la barre de recherche.Esc: Ferme les modales ou efface la recherche.D: Supprime l’observation sélectionnée (doit être ciblée).E: Modifie l’observation sélectionnée.
Limitations et Problèmes Connus de Claude-Mem
Bien que Claude-Mem soit un puissant moteur de productivité, il présente des contraintes techniques spécifiques et des particularités architecturales dont je veux que vous soyez conscient. La transparence est primordiale.
🛑 Limitations Techniques
- Claude Code uniquement : Il est conçu spécifiquement pour la CLI Anthropic Claude Code. Il ne fonctionne pas avec la version web (claude.ai) ou l’application de bureau.
- Stockage local uniquement : Les souvenirs sont stockés sur votre disque dur. Si vous changez d’ordinateur, votre “mémoire” ne vous suivra pas à moins que vous ne déplaciez manuellement les fichiers de la base de données.
- Dépendance au Worker : Si le processus en arrière-plan
claude-mem-workerplante ou n’est pas démarré, le plugin échoue silencieusement ou génère des erreurs de connexion. - Coût des Jetons : Bien qu’il réduise les jetons de 95 % via la compression, l’acte initial de résumé utilise toujours des jetons de votre quota d’API Anthropic. C’est un coût à considérer.
⚠️ Problèmes Connus et Particularités
1. “Ivresse du Contexte”
Si vous avez trop d’observations, Claude peut devenir “confus” par des informations contradictoires (par exemple, une observation d’il y a deux semaines disant d’utiliser le Port 3000 contre une nouvelle disant le Port 5000).
Correction : Élaguer régulièrement les anciennes observations dans l’interface web.
2. “Flou” de la Recherche
La recherche sémantique (recherche vectorielle) n’est pas parfaite. Parfois, demander “Comment me connecter ?” pourrait faire apparaître une session sur “Déconnexion” car les mots sont mathématiquement similaires. C’est un défi inhérent à l’IA.
Correction : Soyez très précis dans vos requêtes de recherche (par exemple, “Logique de connexion JWT”).
3. Délai de Résumé
Il y a un léger délai à la fin d’une session ou d’une tâche pendant que le worker traite et résume les journaux. Si vous quittez le terminal (Ctrl+C) trop rapidement, la mémoire pourrait ne pas être enregistrée.
4. Verrouillage de la Base de Données
Si vous avez plusieurs onglets de terminal ouverts avec Claude Code exécuté dans le même projet, la base de données SQLite peut occasionnellement se “verrouiller”, empêchant l’écriture de nouvelles mémoires.
📉 Contraintes de Performance
- Taille de la Base de Données : À mesure que votre historique s’allonge (des milliers d’observations), l’interface web locale et les vitesses de recherche peuvent ralentir.
- “Amnésie” du Modèle : Claude a une “fenêtre de contexte” finie. Même avec le plugin, si vous chargez 50 mémoires détaillées à la fois, Claude perdra le fil de la conversation actuelle.
🛡️ Bonnes Pratiques pour Éviter les Problèmes
- Utilisez les balises
<private>: Il ne peut pas “dés-voir” un secret une fois qu’il est indexé dans le magasin de vecteurs sans une suppression manuelle. Prévenez plutôt que guérir. - Réinitialisations Périodiques : Pour les phases de projet entièrement nouvelles, envisagez de vider la mémoire spécifique au projet pour garder le contexte “propre”.
Gestion du Stockage et des Performances pour les Projets d’Envergure
À mesure que vos projets grandissent, gérer le stockage et les performances de Claude-Mem devient crucial pour éviter les ralentissements ou l'”encombrement du contexte”. Je vous donne les clés pour maintenir une IA performante.
💾 Sauvegarde et Récupération Manuelles
Claude-Mem stocke son “cerveau” dans deux emplacements locaux principaux. Les sauvegarder manuellement garantit que vous ne perdez pas l’historique du projet lors d’un crash système ou d’une migration.
- Localisez vos données : Toutes les données sont stockées par défaut dans
~/.claude-mem/. - Les fichiers à copier :
claude-mem.db: La base de données SQLite contenant toutes les observations textuelles et les journaux de session.vector_store/(ouchroma/) : Le dossier contenant les “embeddings” mathématiques utilisés pour la recherche sémantique.
- Comment sauvegarder :
- Arrêtez le worker :
claude-mem-worker stop. - Compressez le dossier :
tar -czvf claude-mem-backup.tar.gz ~/.claude-mem/. - Stockez ce fichier sur un lecteur cloud ou un disque externe.
- Arrêtez le worker :
- Comment restaurer : Remplacez le contenu d’un dossier
~/.claude-mem/vierge par vos fichiers sauvegardés et redémarrez le worker.
⚡ Optimisation des Performances pour les Grands Projets
Pour les projets avec des milliers de fichiers ou de longs historiques, utilisez ces paramètres pour maintenir les temps de recherche sous 100 ms et minimiser les coûts de jetons. C’est une question d’ingénierie fine.
1. Optimisation des Jetons (Divulgation Progressive)
Plutôt que de charger des mémoires complètes en une seule fois, Claude-Mem utilise un flux de travail à 3 couches pour économiser jusqu’à 90 % sur l’utilisation des jetons :
- Couche 1 (Recherche) : Claude ne récupère qu’un index compact d’identifiants et de titres (~50 jetons).
- Couche 2 (Chronologie) : Il récupère le contexte chronologique uniquement si le résultat de la recherche semble prometteur.
- Couche 3 (Détail) : Les détails complets de l’observation (~500+ jetons) ne sont récupérés que lorsque Claude les demande spécifiquement.
2. Ajustements du Fichier de Configuration
Modifiez ~/.claude-mem/settings.json (ou utilisez l’interface web sur localhost:37777) pour ajuster ces valeurs :
max_observations: Diminuez-le à 3-5 pour les grands projets afin d’éviter le débordement de la fenêtre de contexte.min_similarity_score: Augmentez-le à 0.8 pour vous assurer que seules les mémoires très pertinentes sont extraites.summary_level: Définissez-le surbriefpour garder les injections de session initiales petites.
🏗️ Gestion de l’Échelle
- Archives Mensuelles : Si une phase de projet est terminée, utilisez la fonction d’exportation pour enregistrer les mémoires dans un fichier
.md, puis utilisezclaude-mem-worker clear --project [nom]pour rafraîchir la mémoire “chaude”. - Score de Fichier : Certaines configurations avancées utilisent des “scores d’attention” où les fichiers fréquemment utilisés sont conservés en mémoire tandis que les fichiers “froids” sont expulsés.
Claude-Mem vs. Mémoire Intégrée et Alternatives
Bien que Claude Code et l’interface web Claude.ai aient des moyens rudimentaires de “se souvenir” des choses, Claude-Mem est un outil tiers puissant pour les utilisateurs qui désirent un cerveau entièrement automatisé et inter-sessions. C’est une distinction importante à faire.
🥊 Claude-Mem vs. Fonctionnalités Intégrées
| Fonctionnalité | Claude-Mem (Plugin) | Claude Code (Intégré) | Claude.ai (Web/Bureau) |
|---|---|---|---|
| Automatisation | Entièrement automatique : Résume le travail une fois la tâche terminée. | Manuelle : Vous devez écrire dans CLAUDE.md. | Semi-automatique : “Instructions de projet” (Manuelles). |
| Persistance | Infinie : Stocke des années de données dans une base de données locale. | Basée sur la session : Oublie une fois la CLI fermée. | Basée sur le projet : Limitée à un conteneur “Projet”. |
| Recherche | Sémantique : Trouve “la correction d’authentification” par signification. | Basée sur les fichiers : Limitée à grep ou à la lecture de fichiers. | Mots-clés : Recherche basique au sein d’un projet. |
| Coût en Jetons | Faible : Compresse les journaux jusqu’à 95 %. | Élevé : Charge des fichiers entiers dans le contexte. | Modéré : Les instructions de projet restent dans le contexte. |
🔍 Alternatives Clés
1. L’Approche “Manuelle” (CLAUDE.md)
La recommandation officielle d’Anthropic. Vous maintenez un fichier nommé CLAUDE.md dans votre dossier racine.
- Idéal pour : Les petites équipes qui veulent une “source de vérité” que tout le monde (y compris les développeurs humains) peut lire.
- Inconvénient : Vous devez vous souvenir de le mettre à jour vous-même. C’est un effort conscient.
2. Mem0 (Anciennement EmbedChain)
Une couche de mémoire robuste pour les agents IA.
- Idéal pour : Les développeurs qui construisent leurs propres agents IA personnalisés, et pas seulement en utilisant Claude Code.
- Différence : Beaucoup plus complexe à configurer ; nécessite une configuration de base de données vectorielle cloud ou locale à partir de zéro.
3. Continual (Extension VS Code)
Une extension qui fournit une mémoire à long terme pour les interactions IA basées sur VS Code.
- Idéal pour : Les personnes qui préfèrent travailler dans une GUI/IDE plutôt que dans une CLI basée sur le terminal comme Claude Code.
4. Cursor (IDE)
Bien qu’il ne s’agisse pas d’un “plugin”, Cursor est un fork de VS Code avec des fonctionnalités “Index”.
- Idéal pour : Les utilisateurs qui veulent une expérience “mémoire” transparente et tout-en-un sans gérer un worker en arrière-plan ou une CLI.
🏆 Lequel Devriez-Vous Utiliser ?
- Utilisez Claude-Mem si vous vivez dans le terminal, détestez la documentation manuelle et voulez un “assistant personnel” qui n’oublie jamais une correction de bug.
- Utilisez CLAUDE.md si vous voulez garder votre projet standard et ne souhaitez pas installer de services d’arrière-plan supplémentaires.
- Utilisez Cursor si vous préférez un IDE visuel et que cela ne vous dérange pas de vous éloigner de l’application VS Code standard.