Le prompt engineering, je le vois comme un pont. Un pont que je construis entre ma pensée et le vaste potentiel des modèles d’IA générative. C’est le processus par lequel je conçois, j’affine et j’optimise mes instructions pour guider ces modèles, comme les grands modèles de langage (LLM), vers des résultats précis, utiles et percutants.
Pour moi, c’est un mélange fascinant d’art et de science, où la créativité linguistique rencontre une compréhension technique du fonctionnement profond de l’IA.
Objectif Principal : Atteindre la Précision
Mon but ultime est simple : fournir à l’IA le contexte, les instructions et les contraintes nécessaires. Je veux m’assurer que la sortie correspondra exactement à mes attentes. C’est un dialogue constant, une danse itérative. Rarement un “one-and-done”, plutôt un cycle continu où je teste une invite, j’évalue sa réponse, puis je peaufine mon texte pour améliorer la performance.
Dans les applications professionnelles, je sais que les ingénieurs créent des “base prompts” – des modèles cachés qui enveloppent l’entrée de l’utilisateur pour garantir un ton, un format et un niveau de précision constants. Une vraie carapace de protection.
Pourquoi cette Discipline est Cruciale pour Moi
Les modèles d’IA générative sont des entités imprévisibles, non déterministes. Cela signifie que la même requête peut donner des résultats différents à chaque fois. J’utilise l’ingénierie d’invites pour dompter cette imprévisibilité.
Je réduis les “hallucinations” de l’IA – ces informations fausses qu’elle invente – et j’atténue les biais inhérents à ses données d’entraînement. De plus, avec des formats et délimiteurs spécifiques, le prompt engineering agit comme une couche de sécurité vitale contre les attaques par “injection d’invite”.
C’est ma pratique quotidienne pour concevoir et affiner des instructions, orientant les LLM vers des sorties plus exactes et plus utiles.
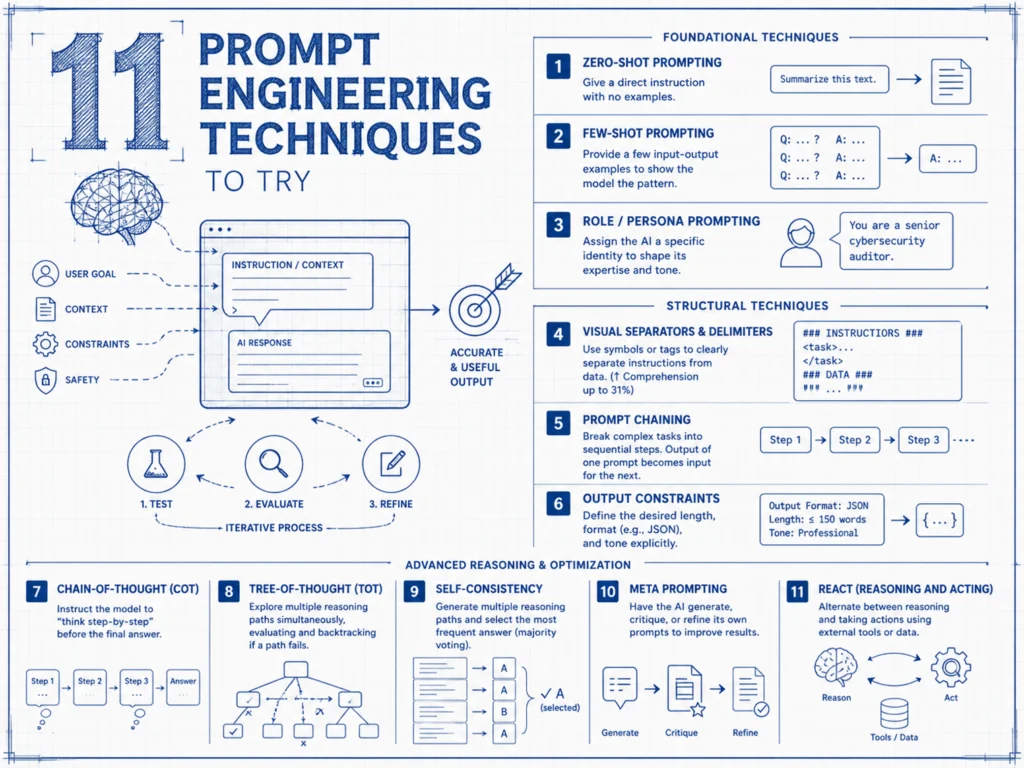
En 2026, je vois ces techniques classées en méthodes fondamentales, structurelles et de raisonnement avancé. C’est une discipline en constante évolution.
Top 11 techniques de prompt engineering à tester
Je commence toujours par les bases. Ces techniques sont les piliers de toute bonne interaction avec l’IA.
Prompting Zero-Shot : La Simplicité Brute
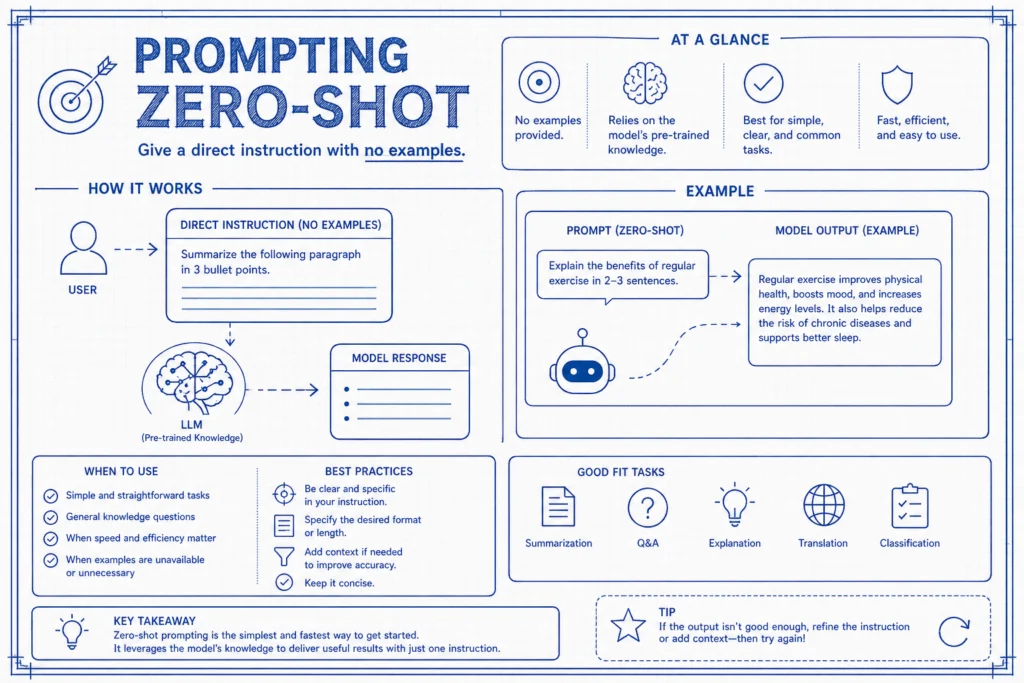
Le zero-shot prompting est ma technique la plus directe. Je donne une instruction ou une question à un modèle d’IA sans fournir le moindre exemple. Le modèle doit se fier entièrement à ses connaissances pré-entraînées et à ses capacités linguistiques générales pour déduire la bonne réponse. C’est la voie rapide, souvent surprenante.
Caractéristiques Clés :
- Zéro Exemple : À l’opposé du “few-shot”, le zero-shot mise tout sur la clarté de mon instruction.
- Rapidité et Simplicité : C’est la méthode la plus rapide pour obtenir une réponse. Elle est hautement scalable car elle ne demande aucune préparation de données spécialisée.
- Dépendance à l’Instruction : La qualité de la sortie dépend entièrement de la clarté et de la spécificité de mes consignes.
Exemples que j’utilise souvent :
- Classification : “Classe le texte suivant comme positif, négatif ou neutre : ‘J’adore ce produit !'”
- Traduction : “Traduis ‘Hello, how are you?’ en français.”
- Résumé : “Résume les points clés de cet article en trois puces.”
- Raisonnement : “Quelle est la capitale de la France ?”
Je l’utilise pour des tâches généralisées où une compréhension large suffit et où la vitesse prime sur une précision extrême. C’est mon point de référence initial pour évaluer la capacité d’un modèle avant de passer à des techniques plus complexes comme le few-shot. Pour en savoir plus sur l’apprentissage zero-shot, je consulte aussi Microsoft Learn.
Mes Limites :
- Moins de Précision : Cela peut échouer avec des domaines très spécialisés ou des raisonnements complexes en plusieurs étapes.
- Sensibilité : Un léger changement dans le libellé peut altérer significativement l’interprétation du modèle et la qualité de la sortie.
- Problèmes de Format : Sans exemples, le modèle ne suivra pas toujours une structure de sortie désirée (comme un schéma JSON spécifique) de manière fiable.
Prompting Few-Shot : Guider l’IA par l’Exemple
Avec le few-shot prompting, je donne à l’IA quelques exemples (généralement 2 à 5) pour lui montrer exactement la réponse que j’attends. Tandis que le zero-shot dit “Fais ça”, le few-shot dit “Fais ça, et voici à quoi la sortie doit ressembler”. C’est un peu comme apprendre à un enfant par mimétisme.
Comment ça Fonctionne :
Je fournis des paires d’entrée et de sortie avant de donner mon instruction finale. Cela “conditionne” le modèle à suivre un schéma, un ton ou un format spécifique qu’il n’aurait peut-être pas choisi naturellement.
Prompt :
"Convertis ces phrases en langage commercial formel :
Input : 'Je suis désolé, je ne peux pas venir.'
Output : 'Veuillez accepter mes excuses ; je ne pourrai pas être présent.'
Input : 'Jette un œil à ça plus tard.'
Output : 'Je vous serais reconnaissant de bien vouloir examiner ceci à votre plus proche convenance.'
Input : 'Je m'en occupe bientôt.'
Output :"
Résultat de l’IA : “Je veillerai à ce que cette tâche soit accomplie en temps opportun.”
Pourquoi c’est Mieux que le Zero-Shot :
- Cohérence : Cela ancre l’IA dans une structure spécifique (comme JSON, CSV ou un style de puces particulier).
- Logique Complexe : Cela aide le modèle à saisir des règles “implicites” ou un jargon spécialisé.
- Nuance : C’est excellent pour imiter la voix unique d’une marque ou le style d’écriture spécifique d’une personne.
Quand je l’utilise :
- Quand j’ai besoin d’un format très spécifique que l’IA ne parvient pas à reproduire.
- Quand la tâche est très subjective (par exemple, “Écris un tweet amusant dans le style de [Humoriste Spécifique]”).
- Lorsque j’utilise des modèles plus petits ou moins performants qui nécessitent plus de “coup de main” qu’un modèle phare comme GPT-4o ou Claude 3.5 et Claude Opus.
La “Règle de Boucle d’or” :
N’en faites pas trop. Fournir 20 exemples est généralement excessif et gaspille des “tokens” (la mémoire du modèle). Généralement, 3 à 5 exemples diversifiés suffisent pour faire le travail. C’est l’équilibre parfait, ni trop, ni trop peu.
Prompting par Rôle/Persona : Quand l’IA Enfile un Costume
Le prompting par rôle ou persona, c’est l’acte de dire à l’IA “agis en tant que” ou “deviens” un personnage, un professionnel ou un expert spécifique. En définissant une persona, je réduis efficacement le champ d’action du modèle, puisant dans un sous-ensemble spécifique de ses données d’entraînement pour influencer son ton, sa profondeur et son vocabulaire.
La Formule de Base :
Au lieu de simplement demander une information, j’enveloppe ma requête dans un contexte :
“Tu es un [Rôle]. Ta tâche est de [Tâche]. Ton public est [Cible]. Utilise un style [Ton].”
Pourquoi ça Fonctionne :
- Contrôle du Ton : Un “Bot de Support” sonne empathique ; un “Coach de Débat” sonne critique et logique.
- Niveau d’Expertise : Si je dis à l’IA qu’elle est un “Physicien Quantique expliquant à un enfant de 5 ans”, elle évitera le jargon. Si je dis “Chercheur Scientifique Senior”, elle utilisera des termes techniques.
- Garde-fous Contextuels : Cela aide l’IA à rester “dans son rôle” pendant la durée d’une conversation, ce qui est formidable pour le jeu de rôle ou le service client spécialisé.
Exemples en Action :
| Objectif | Invite Persona | Ambiance Résultante |
|---|---|---|
| Revue de Code | “Agis en tant qu’Ingénieur Sécurité Senior réalisant un audit de code.” | Se concentre sur les vulnérabilités et les meilleures pratiques. |
| Cuisine | “Tu es un chef italien de renommée mondiale, très impatient.” | Utilise des termes culinaires, se concentre sur la technique, et pourrait être un peu sarcastique. |
| Préparation Entretien | “Agis en tant que responsable du recrutement pour une Grande Entreprise Technologique m’interviewant pour un poste de chef de produit.” | Pose des questions difficiles, basées sur le comportement. |
Mon Conseil Pro : Ajoutez des Contraintes
Pour qu’une persona soit vraiment efficace, j’ajoute des règles au rôle.
- Mauvaise Persona : “Agis en tant qu’agent de voyages.”
- Bonne Persona : “Agis en tant qu’agent de voyages de luxe. Concentre-toi uniquement sur les hôtels-boutiques haut de gamme. Ne suggère jamais d’options économiques. Sois extrêmement poli et formel.”
Mes Techniques Structurelles pour une IA Organisée
Au-delà de la simple instruction, la manière dont je structure mes invites fait toute la différence. C’est l’architecture qui soutient la clarté.
Séparateurs Visuels & Délimiteurs
Les séparateurs visuels et les délimiteurs sont des marqueurs spéciaux, des symboles ou des balises que j’utilise pour définir des limites claires entre les différentes sections d’une invite.
En organisant les instructions, le contexte et les données en blocs logiques, j’aide les grands modèles de langage (LLM) à analyser les informations plus précisément.
Cela prévient la “fuite de contexte”, où des parties non liées d’une invite se mélangent. Une sorte de ponctuation magique.
Types Courants de Délimiteurs :
| Type de Délimiteur | Syntaxe | Meilleure Utilisation |
|---|---|---|
| Triple backticks | “` | Enfermer des extraits de code pour préserver le formatage et la syntaxe. |
| Balises XML/HTML | <tag>…</tag> | Fournir une structure sémantique pour des invites complexes et multi-parties (très efficace pour des modèles comme Claude). |
| Triple guillemets | “”” | Encapsuler de longues citations ou un texte spécifique à traiter (par exemple, “Résume ceci : “”””). |
| Marqueurs de section | ### ou — | Agir comme des en-têtes visuels pour séparer les sections majeures comme “Instructions” et “Contexte”. |
| Crochets/Accolades | […] ou {…} | Marquer des éléments de données distincts ou des éléments individuels dans une liste. |
Pourquoi Ils Améliorent la Performance :
- Analyse Améliorée : Les modèles identifient les sections distinctes et traitent chacune selon son objectif spécifique.
- Ambigüité Réduite : Marquer clairement où une instruction se termine et où les données commencent élimine toute confusion sur le rôle de chaque composant.
- Précision Accrue : La recherche indique que l’utilisation de séparateurs dans des tâches de raisonnement complexes, comme la Chain-of-Thought, peut augmenter la précision de près de 3%.
- Défense Adversaire : L’utilisation stratégique de délimiteurs réduit de moitié le taux de succès des attaques par injection d’invite.
Exemple Pratique :
Au lieu d’un simple paragraphe, une invite structurée pourrait ressembler à ceci :
### INSTRUCTIONS
Veuillez résumer le document suivant en trois points.
### DATA
"""
[Insérer ici un document de 500 mots]
"""
### OUTPUT FORMAT
Utilisez un ton professionnel et renvoyez le résultat au format JSON.
Enchaînement d’Invites (Prompt Chaining)
Le prompt chaining, c’est la technique que j’utilise pour diviser une tâche complexe en plusieurs sous-tâches plus petites et liées. Au lieu de demander à l’IA de tout faire en une seule invite massive, je prends la sortie de l’Étape 1 et la donne en entrée à l’Étape 2. Pensez-y comme à une chaîne de montage pour votre flux de travail IA. C’est plus méthodique, plus propre.
Pourquoi Utiliser le Chaînage ?
- Précision Plus Élevée : Les modèles sont moins susceptibles de se confondre ou “d’oublier” des instructions lorsqu’ils n’ont qu’une seule chose sur laquelle se concentrer à la fois.
- Meilleur Débogage : Si le résultat final est erroné, je peux facilement voir quelle étape spécifique de la chaîne a échoué.
- Gestion du Contexte : Cela me permet de traiter des quantités massives d’informations qui pourraient autrement dépasser la “mémoire” (fenêtre de contexte) du modèle.
À Quoi Ressemble une Chaîne en Pratique :
Imaginez que je veuille créer un article de blog basé sur une longue transcription YouTube.
- Étape 1 : “Extrais les 5 thèmes clés de cette transcription.”
- Étape 2 : (En utilisant les thèmes de l’Étape 1) “Rédige une ébauche détaillée d’un article de blog basée sur ces 5 thèmes.”
- Étape 3 : (En utilisant l’ébauche de l’Étape 2) “Rédige l’introduction complète et la première section de l’article de blog en utilisant un ton professionnel.”
- Étape 4 : “Examine le texte de l’Étape 3 pour les erreurs grammaticales et l’alignement avec la marque.”
L’Avantage du “Chaining” :
Si j’avais tout demandé en une seule invite, l’IA aurait pu me donner un résumé générique et sauter les détails. En chaînant, je force le modèle à dédier toute sa “puissance de calcul” à chaque étape individuelle. C’est comme diriger une équipe d’experts spécialisés.
Mon Conseil Pro : Le Chaînage Programmatique :
Si je suis développeur, je ne fais pas cela manuellement. Des outils comme LangChain ou LangGraph automatisent ce processus, transmettant automatiquement les variables entre les étapes afin que l’utilisateur ne voie que le résultat final, poli. C’est de la magie moderne.
Contraintes de Sortie
Les contraintes de sortie sont les “règles de la route” spécifiques que je donne à l’IA pour contrôler le format, la longueur et le style exacts de sa réponse. Sans contraintes, l’IA a tendance à être “verbeuse” ou imprévisible. Les contraintes forcent le modèle à filtrer ses connaissances dans une forme très spécifique. C’est ma manière de lui dire d’être… succincte.
Les Trois Principaux Types de Contraintes :
| Type de Contrainte | Exemples d’Instructions |
|---|---|
| Format | “Renvoie les données sous forme d’objet JSON,” “Utilise une table Markdown,” ou “Formate en CSV.” |
| Longueur | “Garde la réponse en dessous de 50 mots,” “Écris exactement 3 phrases,” ou “Utilise pas plus de 5 points.” |
| Négatives (Ce qu’il faut éviter) | “N’utilise pas de jargon,” “Évite d’utiliser le mot ‘exhaustif’,” ou “Exclus tout texte d’introduction.” |
Le Piège de la “Contrainte Négative” :
Les modèles sont historiquement meilleurs pour suivre des instructions positives que négatives. Je l’ai appris à la dure.
- Au lieu de : “Ne sois pas verbeux.”
- Essayez : “Sois concis. Utilise des phrases courtes et un maximum de 100 mots.”
Exemple : Transformer une Invite :
- Invite Faible : “Analyse ce feedback client.” (L’IA pourrait écrire un essai de 5 paragraphes).
- Invite Contrainte : “Analyse ce feedback client. Fournis un résumé d’une phrase du sentiment. Liste les 3 principaux points faibles sous forme de puces. Fournis la sortie dans un tableau Markdown avec les colonnes ‘Problème’ et ‘Gravité’. Contrainte : N’incluez aucun préambule ou ‘Voici l’analyse’.”
Pourquoi Elles Sont Essentielles :
- Automatisation : Si je transmet la sortie de l’IA à un autre programme (comme une feuille Excel ou un site web), le format doit être parfait.
- Lisibilité : Cela prévient le “syndrome du mur de texte”.
- Efficacité des Coûts : Des sorties plus courtes utilisent moins de tokens, ce qui me fait économiser de l’argent si j’utilise une API payante.
Mes Techniques Avancées pour une IA Plus Intelligente
Maintenant, nous passons aux stratégies qui poussent vraiment les capacités de l’IA. C’est ici que le modèle commence à ressembler davantage à un partenaire de réflexion.
Chaîne de Pensée (Chain-of-Thought – CoT) : L’IA qui Réfléchit à Voix Haute
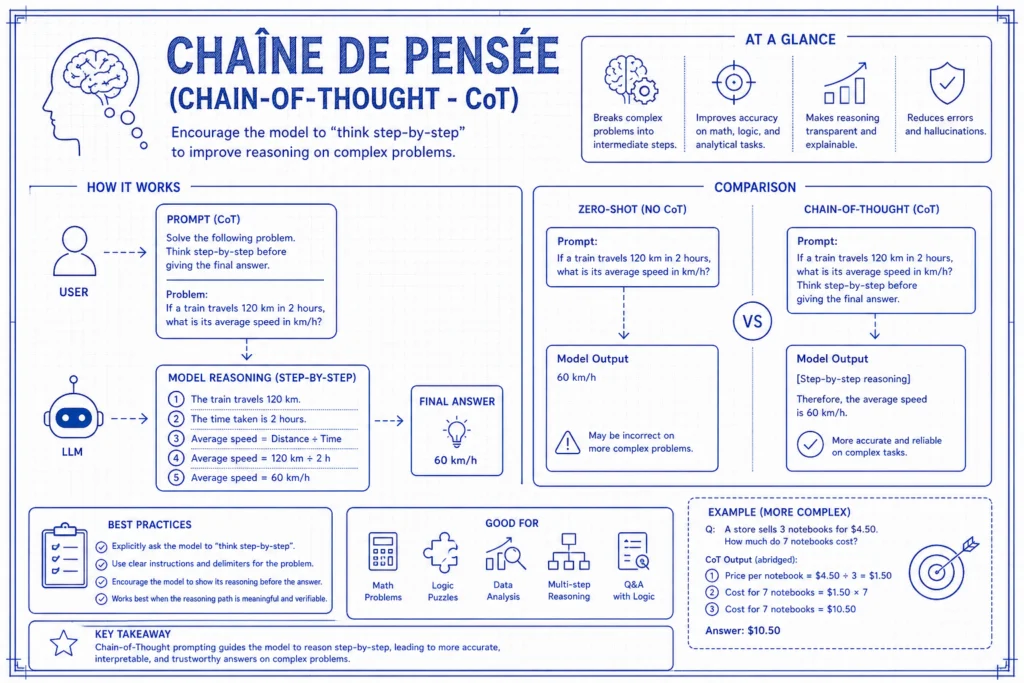
La Chain-of-Thought (CoT) est une technique qui force l’IA à “penser à voix haute” avant de donner une réponse finale. Au lieu de sauter directement à la conclusion, le modèle est incité à parcourir son raisonnement étape par étape.
Cela améliore considérablement les performances sur les tâches impliquant la logique, les mathématiques et la prise de décision en plusieurs étapes. C’est un peu comme regarder un détective résoudre une énigme en me montrant toutes ses pistes.
La “Phrase Magique” :
Le moyen le plus simple de déclencher le CoT est d’ajouter une seule phrase à votre invite :
“Réfléchissons étape par étape.”
Pourquoi ça Fonctionne :
Les LLM prédisent le mot suivant en fonction de ce qui a déjà été écrit. Si un modèle saute directement à une réponse pour un problème de mathématiques difficile, il pourrait se tromper. Si je le force à écrire les étapes intermédiaires, ces étapes deviennent une partie de sa “mémoire de travail”, rendant la réponse finale beaucoup plus susceptible d’être correcte.
CoT Zero-Shot vs. CoT Few-Shot :
- CoT Zero-Shot : Je fournis juste l’instruction et la phrase “étape par étape”.
- CoT Few-Shot : Je fournis 2-3 exemples où je montre le processus de raisonnement. C’est beaucoup plus puissant pour les tâches complexes.
Exemple de Comparaison :
- Invite Standard : “J’ai 5 pommes. J’en donne 2 à mon voisin et j’en achète 12 de plus. Je donne ensuite la moitié de mes pommes à ma sœur. Combien m’en reste-t-il ?” L’IA pourrait potentiellement se tromper si c’est un modèle plus petit.
- Invite CoT : “J’ai 5 pommes. J’en donne 2 à mon voisin et j’en achète 12 de plus. Je donne ensuite la moitié de mes pommes à ma sœur. Combien m’en reste-t-il ? Réfléchissons étape par étape.” Sortie de Raisonnement de l’IA :
Nombre initial : 5 pommes. Après le voisin : 5 - 2 = 3 pommes. Après en avoir acheté plus : 3 + 12 = 15 pommes. Donner la moitié à ma sœur : 15 / 2 = 7.5 pommes. Réponse Finale : Il me reste 7.5 pommes.
Quand je l’utilise :
- Mathématiques et Logique : Problèmes textuels ou calculs complexes.
- Codage : Débogage ou planification de la structure d’un script.
- Analyse de Politiques : Lorsque l’IA doit vérifier une requête par rapport à plusieurs règles différentes.
Arbre de Pensée (Tree-of-Thought – ToT) : L’Exploration Multi-Pistes de l’IA
Le Tree-of-Thought (ToT) est un framework qui améliore le raisonnement de l’IA en permettant aux modèles d’explorer plusieurs chemins de raisonnement simultanément. Contrairement à l’approche linéaire de la Chain-of-Thought, ToT structure la résolution de problèmes comme un arbre de décision où le modèle peut se ramifier, évaluer les étapes individuelles et même revenir en arrière si un chemin mène à une impasse. C’est une exploration plus profonde, plus stratégique.
Composants Clés :
Le framework ToT implique généralement quatre étapes clés :
- Décomposition de la Pensée : Décomposer une tâche complexe en “pensées” ou étapes plus petites et gérables.
- Génération de Pensées : Produire plusieurs étapes potentielles pour chaque état, souvent par échantillonnage ou en proposant différentes idées.
- Évaluation de l’État : Évaluer la qualité de chaque pensée générée à l’aide d’heuristiques, comme l’attribution d’une valeur (par exemple, 1-10) ou le vote sur le chemin le plus prometteur.
- Algorithme de Recherche : Naviguer dans l’arbre en utilisant des méthodes standard comme la recherche en largeur (BFS) ou la recherche en profondeur (DFS) pour trouver la solution optimale.
Bénéfices Clés :
- Planification Délibérée : Imite la pensée “Système 2” humaine – lente, consciente et délibérée – pour gérer des tâches stratégiques.
- Récupération d’Erreurs : En permettant le retour en arrière, le modèle peut abandonner rapidement une logique défectueuse et se concentrer sur des branches plus productives.
- Précision Supérieure : Dans le puzzle mathématique “Jeu des 24”, ToT a atteint un taux de succès de 74%, surpassant largement le prompting standard (7.3%) et la Chain-of-Thought (4%). C’est un gain significatif.
Exemple Pratique : La Technique “Expert” :
Bien que le ToT complet nécessite souvent un code personnalisé, je peux le simuler dans une seule invite en utilisant la technique “Expert” de Vellum :
“Imaginez que trois experts différents répondent à cette question. Tous les experts écriront une étape de leur réflexion, puis la partageront avec le groupe. Si un expert se rend compte qu’il se trompe à un moment donné, il se retire. La question est…”
Quand je l’utilise :
ToT est plus efficace pour les problèmes non linéaires avec un grand espace de recherche, tels que les puzzles Sudoku, les intrigues d’écriture créative, les mots croisés ou la planification logistique complexe. Cependant, il est gourmand en calcul et peut être excessif pour des tâches simples et directes. Il faut choisir son terrain.
Auto-Cohérence (Self-Consistency) : Le Vote Démocratique des Réflexions de l’IA
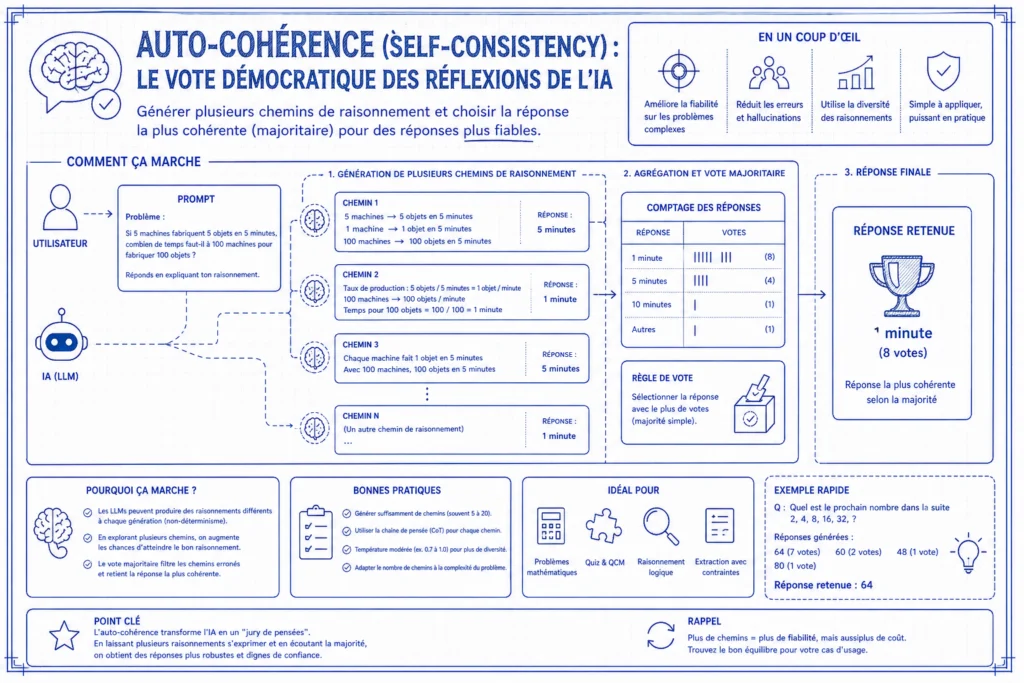
L’auto-cohérence est une technique d’ingénierie d’invites qui améliore la fiabilité des réponses de l’IA en générant plusieurs chemins de raisonnement indépendants et en sélectionnant la réponse la plus fréquente comme résultat final.
Tandis que la Chain-of-Thought (CoT) utilise un seul chemin étape par étape, l’auto-cohérence suppose qu’un problème complexe peut être résolu de nombreuses manières différentes, mais que toutes les manières correctes devraient converger vers la même réponse. C’est une preuve par la majorité.
Le Processus en Trois Étapes :
- Générer Plusieurs Réponses : Le modèle est interrogé plusieurs fois (généralement 5 à 10) en utilisant un réglage de “température” plus élevé pour garantir la diversité des chemins de raisonnement.
- Extraire les Réponses : Chaque réponse inclut son propre raisonnement étape par étape et une réponse finale.
- Vote Majoritaire : Je compte les réponses finales de toutes les réponses. La réponse qui apparaît le plus souvent est sélectionnée comme le résultat “auto-cohérent”.
Pourquoi C’est Important :
- Correction d’Erreurs Intégrée : Si l’IA commet une erreur de calcul dans un chemin, les autres chemins peuvent toujours “outvoter” cette erreur pour atteindre la bonne conclusion.
- Proxy de Confiance : Le degré d’accord sert de signal de fiabilité. Un consensus élevé (par exemple, 9 chemins sur 10 sont d’accord) indique une grande confiance, tandis qu’un vote partagé suggère que le modèle est incertain.
- Gains de Performance : Dans les benchmarks de recherche comme GSM8K (mathématiques), l’auto-cohérence a amélioré la précision de près de 18% par rapport au CoT standard. C’est une amélioration notable, comme le souligne arXiv.
Auto-Cohérence Universelle (USC) :
L’auto-cohérence standard fonctionne mieux pour les réponses fixes comme les chiffres ou les options à choix multiples. Pour les tâches ouvertes comme la résumé, l’auto-cohérence universelle concatène toutes les sorties générées et demande à l’IA de sélectionner la plus cohérente ou la plus détaillée parmi elles. C’est une extension intelligente.
Quand je l’utilise :
- Mathématiques et Logique : Arithmétique en plusieurs étapes où une étape erronée ruine tout le résultat.
- Raisonnement de Bon Sens : Puzzles où plusieurs angles logiques doivent conduire à la même réalité logique.
- Systèmes de Production : Applications critiques où le coût de calcul supplémentaire vaut la garantie d’une réponse vérifiée.
Meta Prompting : L’IA qui Écrit Ses Propres Instructions
Le Meta Prompting est une technique avancée où j’utilise un modèle d’IA pour concevoir, affiner ou optimiser ses propres instructions. Au lieu que j’écrive manuellement chaque détail, je fournis un objectif “méta” de haut niveau, et l’IA agit comme son propre ingénieur d’invites pour construire une invite finale plus efficace. C’est un bond dans l’autonomie de l’IA.
Concept Clé :
Le prompting traditionnel dit à une IA quoi faire (par exemple, “Résume ceci”), tandis que le meta prompting lui dit comment penser ou comment construire un plan pour toute une catégorie de tâches. Il se concentre sur les modèles structurels plutôt que sur le contenu spécifique. C’est le cadre de pensée.
Variations Clés :
- Meta Prompting Récursif (RMP) : Le modèle crée d’abord son propre modèle de raisonnement, puis applique ce modèle pour résoudre le problème. C’est particulièrement puissant pour les tâches complexes et zero-shot où aucun exemple préalable n’existe.
- Prompting par Modèle Conducteur : Un modèle “conducteur” central reçoit un objectif de haut niveau, le décompose en sous-tâches et génère des méta-invites spécialisées pour que différents modèles “experts” les exécutent.
- Ingénierie d’Invites Conversationnelle (CPE) : L’IA m’interviewe, posant des questions spécifiques pour extraire mes exigences et mon contexte, puis génère une invite de haute qualité pour elle-même basée sur mes réponses.
Bénéfices et Avantages :
- Précision & Exactitude : En forçant le modèle à définir explicitement la logique ou les critères d’abord, je réduis significativement les hallucinations et les erreurs logiques dans des domaines très techniques comme le codage ou les mathématiques.
- Efficacité des Tokens : Les méta-invites structurelles peuvent être plus concises que les invites few-shot traditionnelles qui reposent sur de nombreux exemples longs.
- Scalabilité : Une fois qu’un cadre structurel est établi, il peut gérer des milliers de variations au sein d’une catégorie de tâches sans réécriture manuelle.
Cas d’Utilisation Courants :
- Flux de Travail Complexes : Décomposer des projets majeurs en architecture logique et spécifications techniques avant de commencer.
- Standardisation des Sorties : Assurer un comportement cohérent entre les équipes ou les départements, comme le triage de contrats légaux ou la conformité pharmaceutique.
- Auto-Correction : Faire en sorte que l’IA évalue sa propre ébauche initiale par rapport à un ensemble de critères de qualité auto-générés.
ReAct (Reasoning and Acting) : L’IA qui Pense et Agit dans le Monde Réel
ReAct (Reasoning and Acting) est un framework d’ingénierie d’invites qui permet aux grands modèles de langage (LLM) de résoudre des tâches complexes en alternant un raisonnement étape par étape et des actions spécifiques basées sur des outils. Tandis que la Chain-of-Thought (CoT) se concentre sur la pensée interne, ReAct connecte cette pensée au monde réel. C’est l’IA qui sort de sa boîte.
La Boucle ReAct :
Le processus suit un cycle répété de trois étapes fondamentales jusqu’à ce qu’une réponse finale soit atteinte :
- Pensée (Thought) : Le “monologue intérieur” du modèle où il analyse l’état actuel, planifie l’étape suivante ou identifie les informations manquantes.
- Action (Action) : Le modèle choisit un outil spécifique à utiliser, tel qu’une recherche Google, une calculatrice ou un appel d’API, pour interagir avec un environnement externe.
- Observation (Observation) : Le modèle reçoit les données brutes ou la sortie de cette action (par exemple, les résultats de recherche) et les incorpore à son contexte pour éclairer la pensée suivante.
Avantages Clés :
- Réduction des Hallucinations : En ancrant son raisonnement dans des données externes (comme Wikipédia ou des API en direct), le modèle est moins susceptible de fabriquer des faits.
- Planification Dynamique : Le modèle peut ajuster sa stratégie en cours de tâche en fonction de ce qu’il apprend de ses actions.
- Interprétabilité : Il fournit une “trajectoire” transparente de la logique de l’IA, ce qui facilite le débogage et la confiance dans la sortie finale pour les humains.
- Récupération d’Erreurs : Si une action produit un résultat inattendu ou une erreur, la phase de raisonnement permet au modèle de “réagir” et d’essayer une approche différente. Ces avancées sont régulièrement mises en lumière par la recherche de Google.
Cas d’Utilisation Typiques :
- Réponses aux Questions Multi-sauts : Questions qui nécessitent de trouver plusieurs informations provenant de différentes sources.
- Prise de Décision Interactive : Tâches comme naviguer sur WebShop ou des jeux textuels (ALFWorld) où les actions modifient l’environnement.
- Vérification des Faits : Vérifier des affirmations par rapport à des bases de connaissances externes.
Pour une implémentation au niveau de la production, les développeurs utilisent souvent des frameworks d’orchestration comme LangChain ou LangGraph pour gérer automatiquement ces flux de travail “agentiques” complexes. Une vraie symphonie d’IA.
Évaluation et Gestion des Invites
En 2026, l’ingénierie d’invites a évolué, passant de la simple édition de texte à une pratique d’ingénierie disciplinée, soutenue par des plateformes complexes. Ces outils sont généralement classés en fonction de leur objectif : gestion du cycle de vie de bout en bout, tests axés sur les développeurs ou collaboration sans code. C’est l’ère de l’outillage professionnel.
Mes Plateformes d’Évaluation et de Gestion de Pointe en 2026 :
- Braintrust : Souvent citée comme la meilleure plateforme globale pour les équipes d’entreprise. Elle connecte le versionnement des invites directement à la mesure de la qualité, permettant aux équipes de mettre en place des “garde-fous de qualité” qui empêchent les invites peu performantes d’atteindre la production.
- LangSmith : Le choix principal pour les équipes utilisant déjà les frameworks LangChain ou LangGraph. Il fournit un traçage approfondi des comportements complexes des agents et inclut un “Prompt Hub” pour le versionnement et le partage de modèles.
- Maxim AI : Une plateforme d’entreprise complète qui intègre la gestion des invites avec la simulation et l’observabilité. Elle est particulièrement robuste pour les organisations construisant des systèmes multi-agents complexes.
- PromptLayer : Idéal pour les équipes non techniques et les experts du domaine. Il agit comme un CMS visuel pour les invites, permettant aux utilisateurs d’éditer et de déployer des mises à jour sans écrire de code ni attendre les cycles d’ingénierie.
- Langfuse : Une alternative open-source de premier plan qui offre une observabilité et un traçage approfondis. Il est fortement recommandé pour les équipes ayant des exigences strictes en matière de résidence des données qui doivent héberger leur infrastructure elles-mêmes.
Outils Spécialisés pour des Flux de Travail Spécifiques :
| Outil | Catégorie | Point Fort Clé |
|---|---|---|
| Promptfoo | CLI / Open Source | Idéal pour le red-teaming automatisé, l’analyse de sécurité et l’exécution d’évaluations par lots locales. |
| Vellum | Visuel Sans Code | Propose un constructeur de flux de travail visuel qui permet aux utilisateurs non techniques de créer et de tester une logique d’IA complexe. |
| PromptHub | Collaboration d’Équipe | Utilise un flux de travail de type Git (branchement/fusion) pour gérer les changements d’invites en toute sécurité dans des environnements collaboratifs. |
| Humanloop | Évaluation Humaine | Priorise l’annotation experte et les flux de travail “human-in-the-loop” pour une évaluation nuancée de la qualité. |
| PromptPerfect | Optimisation Automatisée | Utilise l’IA pour affiner et optimiser automatiquement les invites existantes sur différents modèles. |
Fonctionnalités Communes des Plateformes :
La plupart des systèmes de gestion professionnels en 2026 incluent les éléments suivants :
- Playgrounds d’Invites : Interfaces côte à côte pour tester différents modèles et variations d’invites simultanément.
- Cadres d’Évaluation : Prise en charge de la notation automatisée à l’aide de “LLM-as-a-judge”, de règles heuristiques (par exemple, validation JSON) et de files d’attente de révision humaine.
- Environnements de Staging/Production : La capacité de promouvoir les invites via des environnements séparés et de revenir sur les changements si la qualité diminue en production.
- Observabilité & Traçage : Journaux détaillés qui connectent des sorties spécifiques à la version exacte de l’invite qui les a générées.
Les 5 Principes Clés de l’Ingénierie d’Invites : Mes Fondations
En 2026, les cinq principes fondamentaux de l’ingénierie d’invites sont reconnus comme une discipline de conception systématique. Ils permettent de transformer de simples requêtes en instructions haute performance. C’est ma boussole, ma feuille de route.
Les 5 Principes Fondamentaux :
- Donner une Direction : Décrire clairement le style ou le résultat souhaité. Attribuer une persona spécifique (par exemple, “Agis en tant que chercheur en sécurité senior”) est un moyen essentiel de guider l’expertise et le ton du modèle.
- Spécifier le Format : Définir la structure exacte requise pour la réponse. Les contraintes courantes incluent la demande de sorties au format JSON, de tableaux Markdown ou de listes numérotées pour garantir que les données sont immédiatement utilisables.
- Fournir des Exemples : Aussi connu sous le nom de few-shot prompting, cela implique l’insertion de cas de test diversifiés de tâches correctement exécutées. Fournir 3 à 5 exemples aide le modèle à comprendre des modèles complexes ou des voix de marque uniques.
- Évaluer la Qualité : Traiter le prompting comme un processus itératif. Je dois systématiquement identifier les erreurs, noter les réponses (souvent sur une échelle de 1 à 10) et ajuster l’invite en fonction des performances.
- Diviser le Travail : Diviser les projets complexes et multi-étapes en sous-tâches plus petites et gérables. Enchaîner ces invites plus petites produit des résultats plus cohérents et précis qu’une seule requête massive.
Comparaison des Frameworks :
Bien que ce soient les principes fondamentaux, d’autres frameworks populaires en 2026 utilisent des variations de ces thèmes :
- Les 5 P’s : Prime (contexte), Persona, Privacy (confidentialité), Product (objectif), et Polish (raffinement).
- Framework CRISP : Context (contexte), Role (rôle), Input (entrée), Steps (étapes), et Parameters (paramètres).
- Context Engineering : Se concentre sur la gestion de la “pile” plus large, y compris les définitions d’outils et les données récupérées à partir d’APIs.
Mon Modèle d’Invite Universel pour l’Action
Voici un modèle d’invite universel que j’ai conçu pour intégrer les 5 principes clés. Vous pouvez le copier-coller, en remplissant les informations entre crochets pour n’importe quelle tâche. C’est ma recette secrète pour des résultats fiables.
### 1. PERSONA (Principe : Donner une Direction)
Vous êtes un expert [par exemple, Rédacteur Technique Senior / Stratège Marketing].
Votre objectif est de [par exemple, expliquer un sujet complexe / créer un e-mail axé sur la conversion].
Votre ton doit être [par exemple, autoritaire mais accessible / énergique et persuasif].
### 2. CONTEXTE & DONNÉES (Principe : Fournir des Exemples/Contexte)
Voici les informations de base dont vous avez besoin :
"""
[Collez votre texte brut, vos données ou votre contexte ici]
"""
Pour vous guider, voici un exemple de la qualité que j'attends :
- Input : [Exemple d'Entrée]
- Output : [Exemple de Sortie]
### 3. LA TÂCHE (Principe : Diviser le Travail)
Suivez ces étapes exactement :
1. D'abord, analysez les données pour [Étape 1].
2. Ensuite, rédigez une version qui se concentre sur [Étape 2].
3. Enfin, affinez le résultat pour vous assurer qu'il respecte [Étape 3].
### 4. CONTRAINTES (Principe : Spécifier le Format)
- Format : Renvoyez la sortie finale sous forme de [par exemple, Tableau Markdown / JSON / 3 Puces].
- Longueur : Gardez la réponse totale sous [par exemple, 200 mots].
- Restrictions : N'utilisez PAS [par exemple, le jargon de l'industrie / la voix passive].
### 5. ÉVALUATION (Principe : Évaluer la Qualité)
Avant de fournir la réponse finale, évaluez votre propre brouillon sur une échelle de 1 à 10 pour la "Clarté".
Si le score est inférieur à 9, réécrivez la section jusqu'à ce qu'elle atteigne ce seuil.
Comment l’utiliser :
Remplacez le texte entre crochets par les détails spécifiques de votre projet. Exécutez l’invite. Évaluez : si l’IA manque un détail, ne demandez pas simplement à nouveau. Mettez à jour le modèle dans la section “Contraintes” ou “Tâche” et réexécutez-le.
C’est ainsi que vous “ingénierez” l’invite pour une utilisation à long terme. C’est ma méthode d’apprentissage constante.
Se Former au Prompt Engineering
Malgré l’importance croissante du prompt engineering, il y a encore très peu d’écoles qui l’enseignent de manière aboutie. Heureusement, certains organismes de formation proposent des programmes pour maîtriser cette discipline.
Par exemple, j’ai trouvé que des bootcamps comme “Prompt Engineering pour Professionnels” proposés par DeepLearn Academy permettent d’acquérir une expertise reconnue en quelques jours, avec une certification à la clé.
Ces formations couvrent les bases du prompt design, des techniques avancées et des cas pratiques avec des modèles comme ChatGPT, Gemini et Claude. C’est un investissement précieux pour quiconque souhaite vraiment maîtriser le dialogue avec l’IA.