L’intelligence artificielle conversationnelle était une étape, pas une destination.
Pendant des années, nous avons optimisé les modèles pour dialoguer. Nous avons mesuré leur capacité à répondre, à expliquer, à converser. Nous avons confondu l’éloquence avec l’utilité.
Mais les agents qui comptent ne discutent pas. Ils exécutent.
FunctionGemma : 270M paramètres dédiés à l’action
FunctionGemma est une version spécialisée de Gemma 3 270M, entraînée pour traduire le langage naturel en appels de fonction structurés.
Pas de personnalité. Pas de conversation inutile. Juste la transformation fiable d’intentions en API.
Le modèle tient sur un téléphone portable. Il fonctionne hors ligne. Il ne transmet rien à un serveur.
Ce qu’il ne fait pas
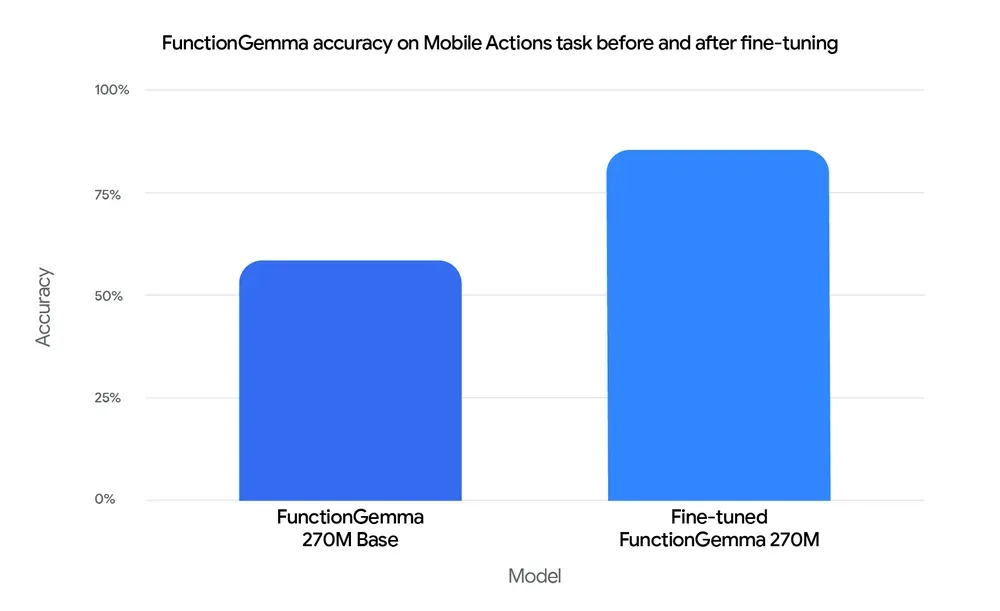
Il ne devine pas. Après fine-tuning, il atteint 85% de précision sur des tâches mobiles définies. Sans fine-tuning, il reste à 58%.
Ce n’est pas un modèle zero-shot universel. C’est une base que vous devez façonner.
Il n’essaie pas d’être général. Il utilise un vocabulaire de 256k tokens optimisé pour JSON et les entrées multilingues. Des séquences courtes. Une latence minimale.
Il ne prétend pas remplacer les grands modèles. Il gère les commandes locales communes. Les requêtes complexes montent vers Gemma 3 27B.
Mécanique interne
Le modèle opère en deux modes :
Mode fonction : Génère des appels structurés (nom de fonction, paramètres JSON) pour exécuter des outils système.
Mode conversation : Résume les résultats en langage naturel après exécution.
Le basculement entre ces modes est déterministe. Le modèle sait quand agir et quand parler.
Exemple concret
Entrée : "Créer un événement calendrier pour déjeuner demain"
Sortie fonction :
{
"function": "createCalendarEvent",
"parameters": {
"title": "Déjeuner",
"date": "2025-12-30",
"time": "12:00"
}
}
Après exécution :
"J'ai créé l'événement. Vous recevrez un rappel."Trois étapes. Aucune ambiguïté. Aucun serveur distant.
Cas d’usage réels
Domotique locale : Un interrupteur ne nécessite pas 175 milliards de paramètres. FunctionGemma route “allume la lumière du salon” vers l’API appropriée, sur l’appareil, en quelques millisecondes.
Applications médicales : Les données des patients ne quittent jamais l’appareil. Le modèle traduit “enregistre tension 120/80” en entrées de base de données structurées, sans connexion internet.
Systèmes industriels embarqués : Sur NVIDIA Jetson Nano, le modèle traite des commandes d’inspection (“capture zone A, détecte défauts”) sans latence réseau.
Jeux interactifs : Le démo TinyGarden prouve qu’un modèle de 270M peut gérer une logique multi-tours (“plante des tournesols en haut et arrose-les”) décomposée en appels de fonction précis.
Ce qui change
Nous passons de l’ère des chatbots à celle des contrôleurs.
Les assistants traditionnels centralisent l’intelligence dans le cloud et envoient du texte. Les agents distribués décentralisent l’exécution à la périphérie et déclenchent des actions.
FunctionGemma représente une architecture différente : le modèle n’est pas le produit. C’est un composant remplaçable dans un système plus large, optimisé pour un rôle étroit.
Spécialisation au lieu de généralisation. Déterminisme au lieu de créativité. Soustraction au lieu d’expansion.
Contraintes assumées
Le modèle nécessite du fine-tuning pour être fiable. Vous devez préparer des données. Vous devez définir votre surface API.
C’est une fonctionnalité, pas un bug. Les agents de production exigent des comportements prévisibles. La variabilité zero-shot n’est pas une vertu quand vous contrôlez des appareils physiques.
Le modèle fonctionne uniquement sur des API définies. Il n’invente pas de nouvelles capacités. Il exécute ce que vous lui enseignez.
Il consomme de la batterie et du calcul. Sur des appareils mobiles, cela compte. Mais l’alternative — interroger constamment le cloud — coûte plus cher en latence et en confidentialité.
Écosystème disponible
Fine-tuning : Hugging Face Transformers, Unsloth, Keras, NVIDIA NeMo
Déploiement : LiteRT-LM, vLLM, MLX, Llama.cpp, Ollama, Vertex AI, LM Studio
Toute la chaîne existe déjà. Aucun outil propriétaire requis.
Accès
Modèle téléchargeable sur Hugging Face, ollama et Kaggle.
Guides disponibles pour les templates d’appel de fonction et le fine-tuning.
L’application Google AI Edge Gallery contient des démos interactives.
Le guide Mobile Actions inclut un notebook Colab et un dataset d’entraînement.
Ce que cela signifie
Les modèles deviennent des primitives, pas des produits.
La valeur se déplace de la taille du modèle vers la précision du système. De la polyvalence vers la spécialisation. De la performance cloud vers l’exécution locale.
300 millions de téléchargements de la famille Gemma ne représentent pas une adoption. Ils représentent une redistribution de l’intelligence vers la périphérie.
Les agents qui comptent ne vivront pas dans des data centers. Ils résideront dans vos poches, vos maisons, vos usines.
Sans connexion. Sans latence. Sans compromis sur la confidentialité.
C’est déjà possible aujourd’hui.